
 alokprasad
4 years ago
alokprasad
4 years ago
66 changed files with 6421 additions and 0 deletions
Unified View
Diff Options
-
+114 -0FastSpeech/.gitignore
-
+21 -0FastSpeech/LICENSE
-
+68 -0FastSpeech/README.md
-
BINFastSpeech/alignments.zip
-
+4 -0FastSpeech/audio/__init__.py
-
+94 -0FastSpeech/audio/audio_processing.py
-
+8 -0FastSpeech/audio/hparams.py
-
+158 -0FastSpeech/audio/stft.py
-
+66 -0FastSpeech/audio/tools.py
-
+34 -0FastSpeech/data/ljspeech.py
-
+124 -0FastSpeech/dataset.py
-
+54 -0FastSpeech/fastspeech.py
-
+317 -0FastSpeech/glow.py
-
+52 -0FastSpeech/hparams.py
-
BINFastSpeech/img/model.png
-
BINFastSpeech/img/model_test.jpg
-
BINFastSpeech/img/tacotron2_outputs.jpg
-
+29 -0FastSpeech/loss.py
-
+404 -0FastSpeech/modules.py
-
+44 -0FastSpeech/optimizer.py
-
+61 -0FastSpeech/preprocess.py
-
BINFastSpeech/results/0.wav
-
BINFastSpeech/results/1.wav
-
BINFastSpeech/results/2.wav
-
+74 -0FastSpeech/synthesis.py
-
+3 -0FastSpeech/tacotron2/__init__.py
-
+92 -0FastSpeech/tacotron2/hparams.py
-
+36 -0FastSpeech/tacotron2/layers.py
-
+533 -0FastSpeech/tacotron2/model.py
-
+29 -0FastSpeech/tacotron2/utils.py
-
+75 -0FastSpeech/text/__init__.py
-
+89 -0FastSpeech/text/cleaners.py
-
+64 -0FastSpeech/text/cmudict.py
-
+71 -0FastSpeech/text/numbers.py
-
+19 -0FastSpeech/text/symbols.py
-
+194 -0FastSpeech/train.py
-
+100 -0FastSpeech/transformer/Beam.py
-
+9 -0FastSpeech/transformer/Constants.py
-
+230 -0FastSpeech/transformer/Layers.py
-
+145 -0FastSpeech/transformer/Models.py
-
+27 -0FastSpeech/transformer/Modules.py
-
+97 -0FastSpeech/transformer/SubLayers.py
-
+6 -0FastSpeech/transformer/__init__.py
-
+183 -0FastSpeech/utils.py
-
+3 -0FastSpeech/waveglow/__init__.py
-
+46 -0FastSpeech/waveglow/convert_model.py
-
+310 -0FastSpeech/waveglow/glow.py
-
+57 -0FastSpeech/waveglow/inference.py
-
+147 -0FastSpeech/waveglow/mel2samp.py
-
+129 -0SqueezeWave/README.md
-
+445 -0SqueezeWave/SqueezeWave_computational_complexity.ipynb
-
+80 -0SqueezeWave/TacotronSTFT.py
-
+93 -0SqueezeWave/audio_processing.py
-
+40 -0SqueezeWave/configs/config_a128_c128.json
-
+40 -0SqueezeWave/configs/config_a128_c256.json
-
+40 -0SqueezeWave/configs/config_a256_c128.json
-
+40 -0SqueezeWave/configs/config_a256_c256.json
-
+70 -0SqueezeWave/convert_model.py
-
+39 -0SqueezeWave/denoiser.py
-
+191 -0SqueezeWave/distributed.py
-
+328 -0SqueezeWave/glow.py
-
+87 -0SqueezeWave/inference.py
-
+150 -0SqueezeWave/mel2samp.py
-
+8 -0SqueezeWave/requirements.txt
-
+147 -0SqueezeWave/stft.py
-
+203 -0SqueezeWave/train.py
+ 114
- 0
FastSpeech/.gitignore
View File
| @ -0,0 +1,114 @@ | |||||
| # Byte-compiled / optimized / DLL files | |||||
| __pycache__/ | |||||
| *.py[cod] | |||||
| *$py.class | |||||
| # C extensions | |||||
| *.so | |||||
| # Distribution / packaging | |||||
| .Python | |||||
| build/ | |||||
| develop-eggs/ | |||||
| dist/ | |||||
| downloads/ | |||||
| eggs/ | |||||
| .eggs/ | |||||
| lib/ | |||||
| lib64/ | |||||
| parts/ | |||||
| sdist/ | |||||
| var/ | |||||
| wheels/ | |||||
| *.egg-info/ | |||||
| .installed.cfg | |||||
| *.egg | |||||
| MANIFEST | |||||
| # PyInstaller | |||||
| # Usually these files are written by a python script from a template | |||||
| # before PyInstaller builds the exe, so as to inject date/other infos into it. | |||||
| *.manifest | |||||
| *.spec | |||||
| # Installer logs | |||||
| pip-log.txt | |||||
| pip-delete-this-directory.txt | |||||
| # Unit test / coverage reports | |||||
| htmlcov/ | |||||
| .tox/ | |||||
| .coverage | |||||
| .coverage.* | |||||
| .cache | |||||
| nosetests.xml | |||||
| coverage.xml | |||||
| *.cover | |||||
| .hypothesis/ | |||||
| .pytest_cache/ | |||||
| # Translations | |||||
| *.mo | |||||
| *.pot | |||||
| # Django stuff: | |||||
| *.log | |||||
| local_settings.py | |||||
| db.sqlite3 | |||||
| # Flask stuff: | |||||
| instance/ | |||||
| .webassets-cache | |||||
| # Scrapy stuff: | |||||
| .scrapy | |||||
| # Sphinx documentation | |||||
| docs/_build/ | |||||
| # PyBuilder | |||||
| target/ | |||||
| # Jupyter Notebook | |||||
| .ipynb_checkpoints | |||||
| # pyenv | |||||
| .python-version | |||||
| # celery beat schedule file | |||||
| celerybeat-schedule | |||||
| # SageMath parsed files | |||||
| *.sage.py | |||||
| # Environments | |||||
| .env | |||||
| .venv | |||||
| env/ | |||||
| venv/ | |||||
| ENV/ | |||||
| env.bak/ | |||||
| venv.bak/ | |||||
| # Spyder project settings | |||||
| .spyderproject | |||||
| .spyproject | |||||
| # Rope project settings | |||||
| .ropeproject | |||||
| # mkdocs documentation | |||||
| /site | |||||
| # mypy | |||||
| .mypy_cache/ | |||||
| __pycache__ | |||||
| .vscode | |||||
| .DS_Store | |||||
| data/train.txt | |||||
| model_new/ | |||||
| mels/ | |||||
| alignments/ | |||||
+ 21
- 0
FastSpeech/LICENSE
View File
| @ -0,0 +1,21 @@ | |||||
| MIT License | |||||
| Copyright (c) 2019 Zhengxi Liu | |||||
| Permission is hereby granted, free of charge, to any person obtaining a copy | |||||
| of this software and associated documentation files (the "Software"), to deal | |||||
| in the Software without restriction, including without limitation the rights | |||||
| to use, copy, modify, merge, publish, distribute, sublicense, and/or sell | |||||
| copies of the Software, and to permit persons to whom the Software is | |||||
| furnished to do so, subject to the following conditions: | |||||
| The above copyright notice and this permission notice shall be included in all | |||||
| copies or substantial portions of the Software. | |||||
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | |||||
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | |||||
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | |||||
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER | |||||
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, | |||||
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE | |||||
| SOFTWARE. | |||||
+ 68
- 0
FastSpeech/README.md
View File
| @ -0,0 +1,68 @@ | |||||
| # FastSpeech-Pytorch | |||||
| The Implementation of FastSpeech Based on Pytorch. | |||||
| ## Update | |||||
| ### 2019/10/23 | |||||
| 1. Fix bugs in alignment; | |||||
| 2. Fix bugs in transformer; | |||||
| 3. Fix bugs in LengthRegulator; | |||||
| 4. Change the way to process audio; | |||||
| 5. Use waveglow to synthesize. | |||||
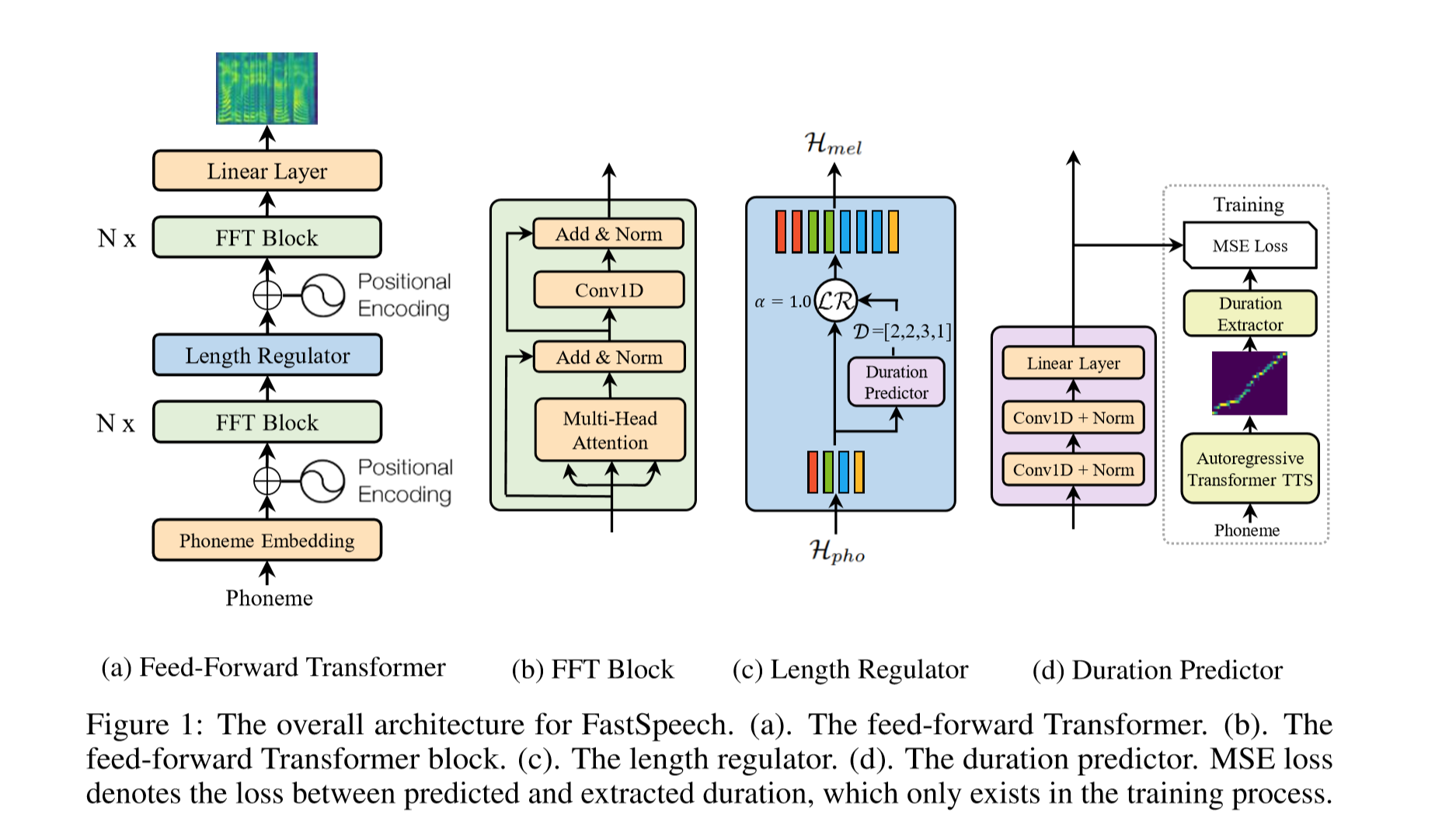
| ## Model | |||||
| <div align="center"> | |||||
| <img src="img/model.png" style="max-width:100%;"> | |||||
| </div> | |||||
| ## My Blog | |||||
| - [FastSpeech Reading Notes](https://zhuanlan.zhihu.com/p/67325775) | |||||
| - [Details and Rethinking of this Implementation](https://zhuanlan.zhihu.com/p/67939482) | |||||
| ## Start | |||||
| ### Dependencies | |||||
| - python 3.6 | |||||
| - CUDA 10.0 | |||||
| - pytorch==1.1.0 | |||||
| - nump==1.16.2 | |||||
| - scipy==1.2.1 | |||||
| - librosa==0.6.3 | |||||
| - inflect==2.1.0 | |||||
| - matplotlib==2.2.2 | |||||
| ### Prepare Dataset | |||||
| 1. Download and extract [LJSpeech dataset](https://keithito.com/LJ-Speech-Dataset/). | |||||
| 2. Put LJSpeech dataset in `data`. | |||||
| 3. Unzip `alignments.zip` \* | |||||
| 4. Put [Nvidia pretrained waveglow model](https://drive.google.com/file/d/1WsibBTsuRg_SF2Z6L6NFRTT-NjEy1oTx/view?usp=sharing) in the `waveglow/pretrained_model`; | |||||
| 5. Run `python preprocess.py`. | |||||
| *\* if you want to calculate alignment, don't unzip alignments.zip and put [Nvidia pretrained Tacotron2 model](https://drive.google.com/file/d/1c5ZTuT7J08wLUoVZ2KkUs_VdZuJ86ZqA/view?usp=sharing) in the `Tacotron2/pretrained_model`* | |||||
| ## Training | |||||
| Run `python train.py`. | |||||
| ## Test | |||||
| Run `python synthesis.py`. | |||||
| ## Pretrained Model | |||||
| - Baidu: [Step:112000](https://pan.baidu.com/s/1by3-8t3A6uihK8K9IFZ7rg) Enter Code: xpk7 | |||||
| - OneDrive: [Step:112000](https://1drv.ms/u/s!AuC2oR4FhoZ29kriYhuodY4-gPsT?e=zUIC8G) | |||||
| ## Notes | |||||
| - In the paper of FastSpeech, authors use pre-trained Transformer-TTS to provide the target of alignment. I didn't have a well-trained Transformer-TTS model so I use Tacotron2 instead. | |||||
| - The examples of audio are in `results`. | |||||
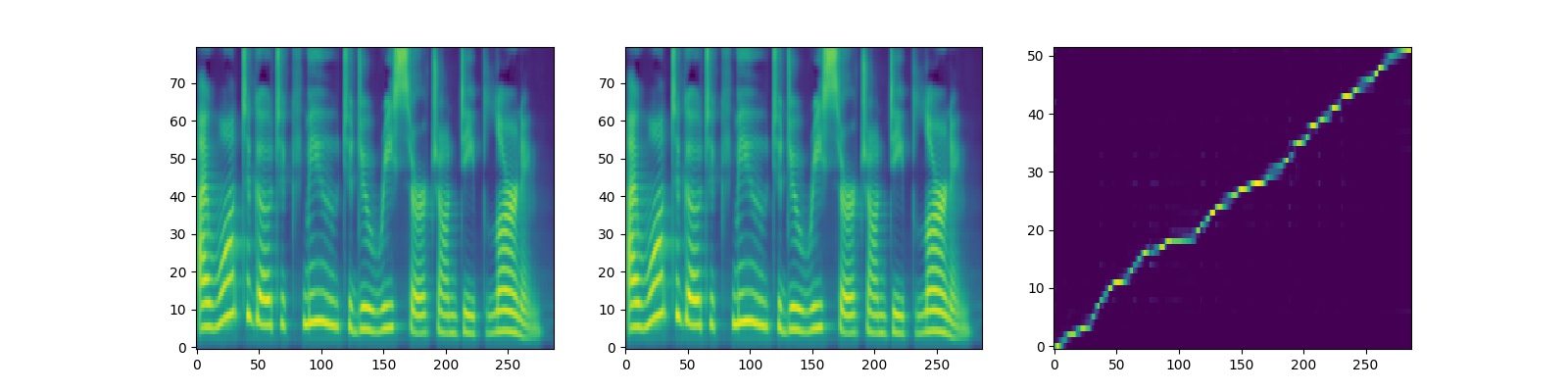
| - The outputs and alignment of Tacotron2 are shown as follows (The sentence for synthesizing is "I want to go to CMU to do research on deep learning."): | |||||
| <div align="center"> | |||||
| <img src="img/tacotron2_outputs.jpg" style="max-width:100%;"> | |||||
| </div> | |||||
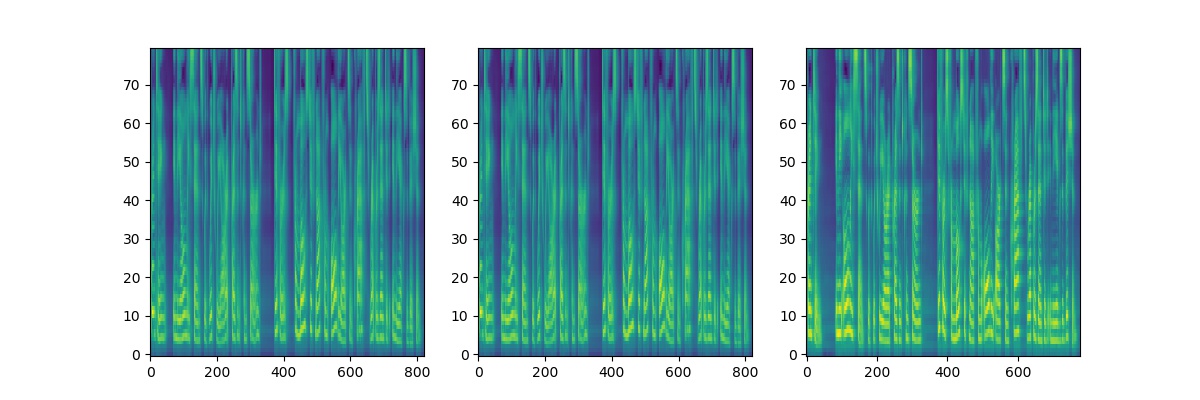
| - The outputs of FastSpeech and Tacotron2 (Right one is tacotron2) are shown as follows (The sentence for synthesizing is "Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition."): | |||||
| <div align="center"> | |||||
| <img src="img/model_test.jpg" style="max-width:100%;"> | |||||
| </div> | |||||
| ## Reference | |||||
| - [The Implementation of Tacotron Based on Tensorflow](https://github.com/keithito/tacotron) | |||||
| - [The Implementation of Transformer Based on Pytorch](https://github.com/jadore801120/attention-is-all-you-need-pytorch) | |||||
| - [The Implementation of Transformer-TTS Based on Pytorch](https://github.com/xcmyz/Transformer-TTS) | |||||
| - [The Implementation of Tacotron2 Based on Pytorch](https://github.com/NVIDIA/tacotron2) | |||||
BIN
FastSpeech/alignments.zip
View File
+ 4
- 0
FastSpeech/audio/__init__.py
View File
| @ -0,0 +1,4 @@ | |||||
| import audio.hparams | |||||
| import audio.tools | |||||
| import audio.stft | |||||
| import audio.audio_processing | |||||
+ 94
- 0
FastSpeech/audio/audio_processing.py
View File
| @ -0,0 +1,94 @@ | |||||
| import torch | |||||
| import numpy as np | |||||
| from scipy.signal import get_window | |||||
| import librosa.util as librosa_util | |||||
| def window_sumsquare(window, n_frames, hop_length=200, win_length=800, | |||||
| n_fft=800, dtype=np.float32, norm=None): | |||||
| """ | |||||
| # from librosa 0.6 | |||||
| Compute the sum-square envelope of a window function at a given hop length. | |||||
| This is used to estimate modulation effects induced by windowing | |||||
| observations in short-time fourier transforms. | |||||
| Parameters | |||||
| ---------- | |||||
| window : string, tuple, number, callable, or list-like | |||||
| Window specification, as in `get_window` | |||||
| n_frames : int > 0 | |||||
| The number of analysis frames | |||||
| hop_length : int > 0 | |||||
| The number of samples to advance between frames | |||||
| win_length : [optional] | |||||
| The length of the window function. By default, this matches `n_fft`. | |||||
| n_fft : int > 0 | |||||
| The length of each analysis frame. | |||||
| dtype : np.dtype | |||||
| The data type of the output | |||||
| Returns | |||||
| ------- | |||||
| wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))` | |||||
| The sum-squared envelope of the window function | |||||
| """ | |||||
| if win_length is None: | |||||
| win_length = n_fft | |||||
| n = n_fft + hop_length * (n_frames - 1) | |||||
| x = np.zeros(n, dtype=dtype) | |||||
| # Compute the squared window at the desired length | |||||
| win_sq = get_window(window, win_length, fftbins=True) | |||||
| win_sq = librosa_util.normalize(win_sq, norm=norm)**2 | |||||
| win_sq = librosa_util.pad_center(win_sq, n_fft) | |||||
| # Fill the envelope | |||||
| for i in range(n_frames): | |||||
| sample = i * hop_length | |||||
| x[sample:min(n, sample + n_fft) | |||||
| ] += win_sq[:max(0, min(n_fft, n - sample))] | |||||
| return x | |||||
| def griffin_lim(magnitudes, stft_fn, n_iters=30): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| magnitudes: spectrogram magnitudes | |||||
| stft_fn: STFT class with transform (STFT) and inverse (ISTFT) methods | |||||
| """ | |||||
| angles = np.angle(np.exp(2j * np.pi * np.random.rand(*magnitudes.size()))) | |||||
| angles = angles.astype(np.float32) | |||||
| angles = torch.autograd.Variable(torch.from_numpy(angles)) | |||||
| signal = stft_fn.inverse(magnitudes, angles).squeeze(1) | |||||
| for i in range(n_iters): | |||||
| _, angles = stft_fn.transform(signal) | |||||
| signal = stft_fn.inverse(magnitudes, angles).squeeze(1) | |||||
| return signal | |||||
| def dynamic_range_compression(x, C=1, clip_val=1e-5): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| C: compression factor | |||||
| """ | |||||
| return torch.log(torch.clamp(x, min=clip_val) * C) | |||||
| def dynamic_range_decompression(x, C=1): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| C: compression factor used to compress | |||||
| """ | |||||
| return torch.exp(x) / C | |||||
+ 8
- 0
FastSpeech/audio/hparams.py
View File
| @ -0,0 +1,8 @@ | |||||
| max_wav_value = 32768.0 | |||||
| sampling_rate = 22050 | |||||
| filter_length = 1024 | |||||
| hop_length = 256 | |||||
| win_length = 1024 | |||||
| n_mel_channels = 80 | |||||
| mel_fmin = 0.0 | |||||
| mel_fmax = 8000.0 | |||||
+ 158
- 0
FastSpeech/audio/stft.py
View File
| @ -0,0 +1,158 @@ | |||||
| import torch | |||||
| import torch.nn.functional as F | |||||
| from torch.autograd import Variable | |||||
| import numpy as np | |||||
| from scipy.signal import get_window | |||||
| from librosa.util import pad_center, tiny | |||||
| from librosa.filters import mel as librosa_mel_fn | |||||
| from audio.audio_processing import dynamic_range_compression | |||||
| from audio.audio_processing import dynamic_range_decompression | |||||
| from audio.audio_processing import window_sumsquare | |||||
| class STFT(torch.nn.Module): | |||||
| """adapted from Prem Seetharaman's https://github.com/pseeth/pytorch-stft""" | |||||
| def __init__(self, filter_length=800, hop_length=200, win_length=800, | |||||
| window='hann'): | |||||
| super(STFT, self).__init__() | |||||
| self.filter_length = filter_length | |||||
| self.hop_length = hop_length | |||||
| self.win_length = win_length | |||||
| self.window = window | |||||
| self.forward_transform = None | |||||
| scale = self.filter_length / self.hop_length | |||||
| fourier_basis = np.fft.fft(np.eye(self.filter_length)) | |||||
| cutoff = int((self.filter_length / 2 + 1)) | |||||
| fourier_basis = np.vstack([np.real(fourier_basis[:cutoff, :]), | |||||
| np.imag(fourier_basis[:cutoff, :])]) | |||||
| forward_basis = torch.FloatTensor(fourier_basis[:, None, :]) | |||||
| inverse_basis = torch.FloatTensor( | |||||
| np.linalg.pinv(scale * fourier_basis).T[:, None, :]) | |||||
| if window is not None: | |||||
| assert(filter_length >= win_length) | |||||
| # get window and zero center pad it to filter_length | |||||
| fft_window = get_window(window, win_length, fftbins=True) | |||||
| fft_window = pad_center(fft_window, filter_length) | |||||
| fft_window = torch.from_numpy(fft_window).float() | |||||
| # window the bases | |||||
| forward_basis *= fft_window | |||||
| inverse_basis *= fft_window | |||||
| self.register_buffer('forward_basis', forward_basis.float()) | |||||
| self.register_buffer('inverse_basis', inverse_basis.float()) | |||||
| def transform(self, input_data): | |||||
| num_batches = input_data.size(0) | |||||
| num_samples = input_data.size(1) | |||||
| self.num_samples = num_samples | |||||
| # similar to librosa, reflect-pad the input | |||||
| input_data = input_data.view(num_batches, 1, num_samples) | |||||
| input_data = F.pad( | |||||
| input_data.unsqueeze(1), | |||||
| (int(self.filter_length / 2), int(self.filter_length / 2), 0, 0), | |||||
| mode='reflect') | |||||
| input_data = input_data.squeeze(1) | |||||
| forward_transform = F.conv1d( | |||||
| input_data.cuda(), | |||||
| Variable(self.forward_basis, requires_grad=False).cuda(), | |||||
| stride=self.hop_length, | |||||
| padding=0).cpu() | |||||
| cutoff = int((self.filter_length / 2) + 1) | |||||
| real_part = forward_transform[:, :cutoff, :] | |||||
| imag_part = forward_transform[:, cutoff:, :] | |||||
| magnitude = torch.sqrt(real_part**2 + imag_part**2) | |||||
| phase = torch.autograd.Variable( | |||||
| torch.atan2(imag_part.data, real_part.data)) | |||||
| return magnitude, phase | |||||
| def inverse(self, magnitude, phase): | |||||
| recombine_magnitude_phase = torch.cat( | |||||
| [magnitude*torch.cos(phase), magnitude*torch.sin(phase)], dim=1) | |||||
| inverse_transform = F.conv_transpose1d( | |||||
| recombine_magnitude_phase, | |||||
| Variable(self.inverse_basis, requires_grad=False), | |||||
| stride=self.hop_length, | |||||
| padding=0) | |||||
| if self.window is not None: | |||||
| window_sum = window_sumsquare( | |||||
| self.window, magnitude.size(-1), hop_length=self.hop_length, | |||||
| win_length=self.win_length, n_fft=self.filter_length, | |||||
| dtype=np.float32) | |||||
| # remove modulation effects | |||||
| approx_nonzero_indices = torch.from_numpy( | |||||
| np.where(window_sum > tiny(window_sum))[0]) | |||||
| window_sum = torch.autograd.Variable( | |||||
| torch.from_numpy(window_sum), requires_grad=False) | |||||
| window_sum = window_sum.cuda() if magnitude.is_cuda else window_sum | |||||
| inverse_transform[:, :, | |||||
| approx_nonzero_indices] /= window_sum[approx_nonzero_indices] | |||||
| # scale by hop ratio | |||||
| inverse_transform *= float(self.filter_length) / self.hop_length | |||||
| inverse_transform = inverse_transform[:, :, int(self.filter_length/2):] | |||||
| inverse_transform = inverse_transform[:, | |||||
| :, :-int(self.filter_length/2):] | |||||
| return inverse_transform | |||||
| def forward(self, input_data): | |||||
| self.magnitude, self.phase = self.transform(input_data) | |||||
| reconstruction = self.inverse(self.magnitude, self.phase) | |||||
| return reconstruction | |||||
| class TacotronSTFT(torch.nn.Module): | |||||
| def __init__(self, filter_length=1024, hop_length=256, win_length=1024, | |||||
| n_mel_channels=80, sampling_rate=22050, mel_fmin=0.0, | |||||
| mel_fmax=8000.0): | |||||
| super(TacotronSTFT, self).__init__() | |||||
| self.n_mel_channels = n_mel_channels | |||||
| self.sampling_rate = sampling_rate | |||||
| self.stft_fn = STFT(filter_length, hop_length, win_length) | |||||
| mel_basis = librosa_mel_fn( | |||||
| sampling_rate, filter_length, n_mel_channels, mel_fmin, mel_fmax) | |||||
| mel_basis = torch.from_numpy(mel_basis).float() | |||||
| self.register_buffer('mel_basis', mel_basis) | |||||
| def spectral_normalize(self, magnitudes): | |||||
| output = dynamic_range_compression(magnitudes) | |||||
| return output | |||||
| def spectral_de_normalize(self, magnitudes): | |||||
| output = dynamic_range_decompression(magnitudes) | |||||
| return output | |||||
| def mel_spectrogram(self, y): | |||||
| """Computes mel-spectrograms from a batch of waves | |||||
| PARAMS | |||||
| ------ | |||||
| y: Variable(torch.FloatTensor) with shape (B, T) in range [-1, 1] | |||||
| RETURNS | |||||
| ------- | |||||
| mel_output: torch.FloatTensor of shape (B, n_mel_channels, T) | |||||
| """ | |||||
| assert(torch.min(y.data) >= -1) | |||||
| assert(torch.max(y.data) <= 1) | |||||
| magnitudes, phases = self.stft_fn.transform(y) | |||||
| magnitudes = magnitudes.data | |||||
| mel_output = torch.matmul(self.mel_basis, magnitudes) | |||||
| mel_output = self.spectral_normalize(mel_output) | |||||
| return mel_output | |||||
+ 66
- 0
FastSpeech/audio/tools.py
View File
| @ -0,0 +1,66 @@ | |||||
| import torch | |||||
| import numpy as np | |||||
| from scipy.io.wavfile import read | |||||
| from scipy.io.wavfile import write | |||||
| import audio.stft as stft | |||||
| import audio.hparams as hparams | |||||
| from audio.audio_processing import griffin_lim | |||||
| _stft = stft.TacotronSTFT( | |||||
| hparams.filter_length, hparams.hop_length, hparams.win_length, | |||||
| hparams.n_mel_channels, hparams.sampling_rate, hparams.mel_fmin, | |||||
| hparams.mel_fmax) | |||||
| def load_wav_to_torch(full_path): | |||||
| sampling_rate, data = read(full_path) | |||||
| return torch.FloatTensor(data.astype(np.float32)), sampling_rate | |||||
| def get_mel(filename): | |||||
| audio, sampling_rate = load_wav_to_torch(filename) | |||||
| if sampling_rate != _stft.sampling_rate: | |||||
| raise ValueError("{} {} SR doesn't match target {} SR".format( | |||||
| sampling_rate, _stft.sampling_rate)) | |||||
| audio_norm = audio / hparams.max_wav_value | |||||
| audio_norm = audio_norm.unsqueeze(0) | |||||
| audio_norm = torch.autograd.Variable(audio_norm, requires_grad=False) | |||||
| melspec = _stft.mel_spectrogram(audio_norm) | |||||
| melspec = torch.squeeze(melspec, 0) | |||||
| # melspec = torch.from_numpy(_normalize(melspec.numpy())) | |||||
| return melspec | |||||
| def get_mel_from_wav(audio): | |||||
| sampling_rate = hparams.sampling_rate | |||||
| if sampling_rate != _stft.sampling_rate: | |||||
| raise ValueError("{} {} SR doesn't match target {} SR".format( | |||||
| sampling_rate, _stft.sampling_rate)) | |||||
| audio_norm = audio / hparams.max_wav_value | |||||
| audio_norm = audio_norm.unsqueeze(0) | |||||
| audio_norm = torch.autograd.Variable(audio_norm, requires_grad=False) | |||||
| melspec = _stft.mel_spectrogram(audio_norm) | |||||
| melspec = torch.squeeze(melspec, 0) | |||||
| return melspec | |||||
| def inv_mel_spec(mel, out_filename, griffin_iters=60): | |||||
| mel = torch.stack([mel]) | |||||
| # mel = torch.stack([torch.from_numpy(_denormalize(mel.numpy()))]) | |||||
| mel_decompress = _stft.spectral_de_normalize(mel) | |||||
| mel_decompress = mel_decompress.transpose(1, 2).data.cpu() | |||||
| spec_from_mel_scaling = 1000 | |||||
| spec_from_mel = torch.mm(mel_decompress[0], _stft.mel_basis) | |||||
| spec_from_mel = spec_from_mel.transpose(0, 1).unsqueeze(0) | |||||
| spec_from_mel = spec_from_mel * spec_from_mel_scaling | |||||
| audio = griffin_lim(torch.autograd.Variable( | |||||
| spec_from_mel[:, :, :-1]), _stft.stft_fn, griffin_iters) | |||||
| audio = audio.squeeze() | |||||
| audio = audio.cpu().numpy() | |||||
| audio_path = out_filename | |||||
| write(audio_path, hparams.sampling_rate, audio) | |||||
+ 34
- 0
FastSpeech/data/ljspeech.py
View File
| @ -0,0 +1,34 @@ | |||||
| import numpy as np | |||||
| import os | |||||
| import audio as Audio | |||||
| def build_from_path(in_dir, out_dir): | |||||
| index = 1 | |||||
| out = list() | |||||
| with open(os.path.join(in_dir, 'metadata.csv'), encoding='utf-8') as f: | |||||
| for line in f: | |||||
| parts = line.strip().split('|') | |||||
| wav_path = os.path.join(in_dir, 'wavs', '%s.wav' % parts[0]) | |||||
| text = parts[2] | |||||
| out.append(_process_utterance(out_dir, index, wav_path, text)) | |||||
| if index % 100 == 0: | |||||
| print("Done %d" % index) | |||||
| index = index + 1 | |||||
| return out | |||||
| def _process_utterance(out_dir, index, wav_path, text): | |||||
| # Compute a mel-scale spectrogram from the wav: | |||||
| mel_spectrogram = Audio.tools.get_mel(wav_path).numpy().astype(np.float32) | |||||
| # print(mel_spectrogram) | |||||
| # Write the spectrograms to disk: | |||||
| mel_filename = 'ljspeech-mel-%05d.npy' % index | |||||
| np.save(os.path.join(out_dir, mel_filename), | |||||
| mel_spectrogram.T, allow_pickle=False) | |||||
| return text | |||||
+ 124
- 0
FastSpeech/dataset.py
View File
| @ -0,0 +1,124 @@ | |||||
| import torch | |||||
| from torch.nn import functional as F | |||||
| from torch.utils.data import Dataset, DataLoader | |||||
| import numpy as np | |||||
| import math | |||||
| import os | |||||
| import hparams | |||||
| import audio as Audio | |||||
| from text import text_to_sequence | |||||
| from utils import process_text, pad_1D, pad_2D | |||||
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') | |||||
| class FastSpeechDataset(Dataset): | |||||
| """ LJSpeech """ | |||||
| def __init__(self): | |||||
| self.text = process_text(os.path.join("data", "train.txt")) | |||||
| def __len__(self): | |||||
| return len(self.text) | |||||
| def __getitem__(self, idx): | |||||
| mel_gt_name = os.path.join( | |||||
| hparams.mel_ground_truth, "ljspeech-mel-%05d.npy" % (idx+1)) | |||||
| mel_gt_target = np.load(mel_gt_name) | |||||
| D = np.load(os.path.join(hparams.alignment_path, str(idx)+".npy")) | |||||
| character = self.text[idx][0:len(self.text[idx])-1] | |||||
| character = np.array(text_to_sequence( | |||||
| character, hparams.text_cleaners)) | |||||
| sample = {"text": character, | |||||
| "mel_target": mel_gt_target, | |||||
| "D": D} | |||||
| return sample | |||||
| def reprocess(batch, cut_list): | |||||
| texts = [batch[ind]["text"] for ind in cut_list] | |||||
| mel_targets = [batch[ind]["mel_target"] for ind in cut_list] | |||||
| Ds = [batch[ind]["D"] for ind in cut_list] | |||||
| length_text = np.array([]) | |||||
| for text in texts: | |||||
| length_text = np.append(length_text, text.shape[0]) | |||||
| src_pos = list() | |||||
| max_len = int(max(length_text)) | |||||
| for length_src_row in length_text: | |||||
| src_pos.append(np.pad([i+1 for i in range(int(length_src_row))], | |||||
| (0, max_len-int(length_src_row)), 'constant')) | |||||
| src_pos = np.array(src_pos) | |||||
| length_mel = np.array(list()) | |||||
| for mel in mel_targets: | |||||
| length_mel = np.append(length_mel, mel.shape[0]) | |||||
| mel_pos = list() | |||||
| max_mel_len = int(max(length_mel)) | |||||
| for length_mel_row in length_mel: | |||||
| mel_pos.append(np.pad([i+1 for i in range(int(length_mel_row))], | |||||
| (0, max_mel_len-int(length_mel_row)), 'constant')) | |||||
| mel_pos = np.array(mel_pos) | |||||
| texts = pad_1D(texts) | |||||
| Ds = pad_1D(Ds) | |||||
| mel_targets = pad_2D(mel_targets) | |||||
| out = {"text": texts, | |||||
| "mel_target": mel_targets, | |||||
| "D": Ds, | |||||
| "mel_pos": mel_pos, | |||||
| "src_pos": src_pos, | |||||
| "mel_max_len": max_mel_len} | |||||
| return out | |||||
| def collate_fn(batch): | |||||
| len_arr = np.array([d["text"].shape[0] for d in batch]) | |||||
| index_arr = np.argsort(-len_arr) | |||||
| batchsize = len(batch) | |||||
| real_batchsize = int(math.sqrt(batchsize)) | |||||
| cut_list = list() | |||||
| for i in range(real_batchsize): | |||||
| cut_list.append(index_arr[i*real_batchsize:(i+1)*real_batchsize]) | |||||
| output = list() | |||||
| for i in range(real_batchsize): | |||||
| output.append(reprocess(batch, cut_list[i])) | |||||
| return output | |||||
| if __name__ == "__main__": | |||||
| # Test | |||||
| dataset = FastSpeechDataset() | |||||
| training_loader = DataLoader(dataset, | |||||
| batch_size=1, | |||||
| shuffle=False, | |||||
| collate_fn=collate_fn, | |||||
| drop_last=True, | |||||
| num_workers=0) | |||||
| total_step = hparams.epochs * len(training_loader) * hparams.batch_size | |||||
| cnt = 0 | |||||
| for i, batchs in enumerate(training_loader): | |||||
| for j, data_of_batch in enumerate(batchs): | |||||
| mel_target = torch.from_numpy( | |||||
| data_of_batch["mel_target"]).float().to(device) | |||||
| D = torch.from_numpy(data_of_batch["D"]).int().to(device) | |||||
| # print(mel_target.size()) | |||||
| # print(D.sum()) | |||||
| print(cnt) | |||||
| if mel_target.size(1) == D.sum().item(): | |||||
| cnt += 1 | |||||
| print(cnt) | |||||
+ 54
- 0
FastSpeech/fastspeech.py
View File
| @ -0,0 +1,54 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| from transformer.Models import Encoder, Decoder | |||||
| from transformer.Layers import Linear, PostNet | |||||
| from modules import LengthRegulator | |||||
| import hparams as hp | |||||
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') | |||||
| class FastSpeech(nn.Module): | |||||
| """ FastSpeech """ | |||||
| def __init__(self): | |||||
| super(FastSpeech, self).__init__() | |||||
| self.encoder = Encoder() | |||||
| self.length_regulator = LengthRegulator() | |||||
| self.decoder = Decoder() | |||||
| self.mel_linear = Linear(hp.decoder_output_size, hp.num_mels) | |||||
| self.postnet = PostNet() | |||||
| def forward(self, src_seq, src_pos, mel_pos=None, mel_max_length=None, length_target=None, alpha=1.0): | |||||
| encoder_output, _ = self.encoder(src_seq, src_pos) | |||||
| if self.training: | |||||
| length_regulator_output, duration_predictor_output = self.length_regulator(encoder_output, | |||||
| target=length_target, | |||||
| alpha=alpha, | |||||
| mel_max_length=mel_max_length) | |||||
| decoder_output = self.decoder(length_regulator_output, mel_pos) | |||||
| mel_output = self.mel_linear(decoder_output) | |||||
| mel_output_postnet = self.postnet(mel_output) + mel_output | |||||
| return mel_output, mel_output_postnet, duration_predictor_output | |||||
| else: | |||||
| length_regulator_output, decoder_pos = self.length_regulator(encoder_output, | |||||
| alpha=alpha) | |||||
| decoder_output = self.decoder(length_regulator_output, decoder_pos) | |||||
| mel_output = self.mel_linear(decoder_output) | |||||
| mel_output_postnet = self.postnet(mel_output) + mel_output | |||||
| return mel_output, mel_output_postnet | |||||
| if __name__ == "__main__": | |||||
| # Test | |||||
| model = FastSpeech() | |||||
| print(sum(param.numel() for param in model.parameters())) | |||||
+ 317
- 0
FastSpeech/glow.py
View File
| @ -0,0 +1,317 @@ | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import copy | |||||
| import torch | |||||
| from torch.autograd import Variable | |||||
| import torch.nn.functional as F | |||||
| @torch.jit.script | |||||
| def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): | |||||
| n_channels_int = n_channels[0] | |||||
| in_act = input_a+input_b | |||||
| t_act = torch.nn.functional.tanh(in_act[:, :n_channels_int, :]) | |||||
| s_act = torch.nn.functional.sigmoid(in_act[:, n_channels_int:, :]) | |||||
| acts = t_act * s_act | |||||
| return acts | |||||
| class WaveGlowLoss(torch.nn.Module): | |||||
| def __init__(self, sigma=1.0): | |||||
| super(WaveGlowLoss, self).__init__() | |||||
| self.sigma = sigma | |||||
| def forward(self, model_output): | |||||
| z, log_s_list, log_det_W_list = model_output | |||||
| for i, log_s in enumerate(log_s_list): | |||||
| if i == 0: | |||||
| log_s_total = torch.sum(log_s) | |||||
| log_det_W_total = log_det_W_list[i] | |||||
| else: | |||||
| log_s_total = log_s_total + torch.sum(log_s) | |||||
| log_det_W_total += log_det_W_list[i] | |||||
| loss = torch.sum(z*z)/(2*self.sigma*self.sigma) - \ | |||||
| log_s_total - log_det_W_total | |||||
| return loss/(z.size(0)*z.size(1)*z.size(2)) | |||||
| class Invertible1x1Conv(torch.nn.Module): | |||||
| """ | |||||
| The layer outputs both the convolution, and the log determinant | |||||
| of its weight matrix. If reverse=True it does convolution with | |||||
| inverse | |||||
| """ | |||||
| def __init__(self, c): | |||||
| super(Invertible1x1Conv, self).__init__() | |||||
| self.conv = torch.nn.Conv1d(c, c, kernel_size=1, stride=1, padding=0, | |||||
| bias=False) | |||||
| # Sample a random orthonormal matrix to initialize weights | |||||
| W = torch.qr(torch.FloatTensor(c, c).normal_())[0] | |||||
| # Ensure determinant is 1.0 not -1.0 | |||||
| if torch.det(W) < 0: | |||||
| W[:, 0] = -1*W[:, 0] | |||||
| W = W.view(c, c, 1) | |||||
| self.conv.weight.data = W | |||||
| def forward(self, z, reverse=False): | |||||
| # shape | |||||
| batch_size, group_size, n_of_groups = z.size() | |||||
| W = self.conv.weight.squeeze() | |||||
| if reverse: | |||||
| if not hasattr(self, 'W_inverse'): | |||||
| # Reverse computation | |||||
| W_inverse = W.inverse() | |||||
| W_inverse = Variable(W_inverse[..., None]) | |||||
| if z.type() == 'torch.cuda.HalfTensor': | |||||
| W_inverse = W_inverse.half() | |||||
| self.W_inverse = W_inverse | |||||
| z = F.conv1d(z, self.W_inverse, bias=None, stride=1, padding=0) | |||||
| return z | |||||
| else: | |||||
| # Forward computation | |||||
| log_det_W = batch_size * n_of_groups * torch.logdet(W) | |||||
| z = self.conv(z) | |||||
| return z, log_det_W | |||||
| class WN(torch.nn.Module): | |||||
| """ | |||||
| This is the WaveNet like layer for the affine coupling. The primary difference | |||||
| from WaveNet is the convolutions need not be causal. There is also no dilation | |||||
| size reset. The dilation only doubles on each layer | |||||
| """ | |||||
| def __init__(self, n_in_channels, n_mel_channels, n_layers, n_channels, | |||||
| kernel_size): | |||||
| super(WN, self).__init__() | |||||
| assert(kernel_size % 2 == 1) | |||||
| assert(n_channels % 2 == 0) | |||||
| self.n_layers = n_layers | |||||
| self.n_channels = n_channels | |||||
| self.in_layers = torch.nn.ModuleList() | |||||
| self.res_skip_layers = torch.nn.ModuleList() | |||||
| self.cond_layers = torch.nn.ModuleList() | |||||
| start = torch.nn.Conv1d(n_in_channels, n_channels, 1) | |||||
| start = torch.nn.utils.weight_norm(start, name='weight') | |||||
| self.start = start | |||||
| # Initializing last layer to 0 makes the affine coupling layers | |||||
| # do nothing at first. This helps with training stability | |||||
| end = torch.nn.Conv1d(n_channels, 2*n_in_channels, 1) | |||||
| end.weight.data.zero_() | |||||
| end.bias.data.zero_() | |||||
| self.end = end | |||||
| for i in range(n_layers): | |||||
| dilation = 2 ** i | |||||
| padding = int((kernel_size*dilation - dilation)/2) | |||||
| in_layer = torch.nn.Conv1d(n_channels, 2*n_channels, kernel_size, | |||||
| dilation=dilation, padding=padding) | |||||
| in_layer = torch.nn.utils.weight_norm(in_layer, name='weight') | |||||
| self.in_layers.append(in_layer) | |||||
| cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels, 1) | |||||
| cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') | |||||
| self.cond_layers.append(cond_layer) | |||||
| # last one is not necessary | |||||
| if i < n_layers - 1: | |||||
| res_skip_channels = 2*n_channels | |||||
| else: | |||||
| res_skip_channels = n_channels | |||||
| res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1) | |||||
| res_skip_layer = torch.nn.utils.weight_norm( | |||||
| res_skip_layer, name='weight') | |||||
| self.res_skip_layers.append(res_skip_layer) | |||||
| def forward(self, forward_input): | |||||
| audio, spect = forward_input | |||||
| audio = self.start(audio) | |||||
| for i in range(self.n_layers): | |||||
| acts = fused_add_tanh_sigmoid_multiply( | |||||
| self.in_layers[i](audio), | |||||
| self.cond_layers[i](spect), | |||||
| torch.IntTensor([self.n_channels])) | |||||
| res_skip_acts = self.res_skip_layers[i](acts) | |||||
| if i < self.n_layers - 1: | |||||
| audio = res_skip_acts[:, :self.n_channels, :] + audio | |||||
| skip_acts = res_skip_acts[:, self.n_channels:, :] | |||||
| else: | |||||
| skip_acts = res_skip_acts | |||||
| if i == 0: | |||||
| output = skip_acts | |||||
| else: | |||||
| output = skip_acts + output | |||||
| return self.end(output) | |||||
| class WaveGlow(torch.nn.Module): | |||||
| def __init__(self, n_mel_channels, n_flows, n_group, n_early_every, | |||||
| n_early_size, WN_config): | |||||
| super(WaveGlow, self).__init__() | |||||
| self.upsample = torch.nn.ConvTranspose1d(n_mel_channels, | |||||
| n_mel_channels, | |||||
| 1024, stride=256) | |||||
| assert(n_group % 2 == 0) | |||||
| self.n_flows = n_flows | |||||
| self.n_group = n_group | |||||
| self.n_early_every = n_early_every | |||||
| self.n_early_size = n_early_size | |||||
| self.WN = torch.nn.ModuleList() | |||||
| self.convinv = torch.nn.ModuleList() | |||||
| n_half = int(n_group/2) | |||||
| # Set up layers with the right sizes based on how many dimensions | |||||
| # have been output already | |||||
| n_remaining_channels = n_group | |||||
| for k in range(n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| n_half = n_half - int(self.n_early_size/2) | |||||
| n_remaining_channels = n_remaining_channels - self.n_early_size | |||||
| self.convinv.append(Invertible1x1Conv(n_remaining_channels)) | |||||
| self.WN.append(WN(n_half, n_mel_channels*n_group, **WN_config)) | |||||
| self.n_remaining_channels = n_remaining_channels # Useful during inference | |||||
| def forward(self, forward_input): | |||||
| """ | |||||
| forward_input[0] = mel_spectrogram: batch x n_mel_channels x frames | |||||
| forward_input[1] = audio: batch x time | |||||
| """ | |||||
| spect, audio = forward_input | |||||
| # Upsample spectrogram to size of audio | |||||
| spect = self.upsample(spect) | |||||
| assert(spect.size(2) >= audio.size(1)) | |||||
| if spect.size(2) > audio.size(1): | |||||
| spect = spect[:, :, :audio.size(1)] | |||||
| spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3) | |||||
| spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1) | |||||
| audio = audio.unfold(1, self.n_group, self.n_group).permute(0, 2, 1) | |||||
| output_audio = [] | |||||
| log_s_list = [] | |||||
| log_det_W_list = [] | |||||
| for k in range(self.n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| output_audio.append(audio[:, :self.n_early_size, :]) | |||||
| audio = audio[:, self.n_early_size:, :] | |||||
| audio, log_det_W = self.convinv[k](audio) | |||||
| log_det_W_list.append(log_det_W) | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:, :n_half, :] | |||||
| audio_1 = audio[:, n_half:, :] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| log_s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = torch.exp(log_s)*audio_1 + b | |||||
| log_s_list.append(log_s) | |||||
| audio = torch.cat([audio_0, audio_1], 1) | |||||
| output_audio.append(audio) | |||||
| return torch.cat(output_audio, 1), log_s_list, log_det_W_list | |||||
| def infer(self, spect, sigma=1.0): | |||||
| spect = self.upsample(spect) | |||||
| # trim conv artifacts. maybe pad spec to kernel multiple | |||||
| time_cutoff = self.upsample.kernel_size[0] - self.upsample.stride[0] | |||||
| spect = spect[:, :, :-time_cutoff] | |||||
| spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3) | |||||
| spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1) | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| audio = torch.cuda.HalfTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| spect.size(2)).normal_() | |||||
| else: | |||||
| audio = torch.cuda.FloatTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| spect.size(2)).normal_() | |||||
| audio = torch.autograd.Variable(sigma*audio) | |||||
| for k in reversed(range(self.n_flows)): | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:, :n_half, :] | |||||
| audio_1 = audio[:, n_half:, :] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = (audio_1 - b)/torch.exp(s) | |||||
| audio = torch.cat([audio_0, audio_1], 1) | |||||
| audio = self.convinv[k](audio, reverse=True) | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| z = torch.cuda.HalfTensor(spect.size( | |||||
| 0), self.n_early_size, spect.size(2)).normal_() | |||||
| else: | |||||
| z = torch.cuda.FloatTensor(spect.size( | |||||
| 0), self.n_early_size, spect.size(2)).normal_() | |||||
| audio = torch.cat((sigma*z, audio), 1) | |||||
| audio = audio.permute(0, 2, 1).contiguous().view( | |||||
| audio.size(0), -1).data | |||||
| return audio | |||||
| @staticmethod | |||||
| def remove_weightnorm(model): | |||||
| waveglow = model | |||||
| for WN in waveglow.WN: | |||||
| WN.start = torch.nn.utils.remove_weight_norm(WN.start) | |||||
| WN.in_layers = remove(WN.in_layers) | |||||
| WN.cond_layers = remove(WN.cond_layers) | |||||
| WN.res_skip_layers = remove(WN.res_skip_layers) | |||||
| return waveglow | |||||
| def remove(conv_list): | |||||
| new_conv_list = torch.nn.ModuleList() | |||||
| for old_conv in conv_list: | |||||
| old_conv = torch.nn.utils.remove_weight_norm(old_conv) | |||||
| new_conv_list.append(old_conv) | |||||
| return new_conv_list | |||||
+ 52
- 0
FastSpeech/hparams.py
View File
| @ -0,0 +1,52 @@ | |||||
| from text import symbols | |||||
| # Text | |||||
| text_cleaners = ['english_cleaners'] | |||||
| # Mel | |||||
| n_mel_channels = 80 | |||||
| num_mels = 80 | |||||
| # FastSpeech | |||||
| vocab_size = 1024 | |||||
| N = 6 | |||||
| Head = 2 | |||||
| d_model = 384 | |||||
| duration_predictor_filter_size = 256 | |||||
| duration_predictor_kernel_size = 3 | |||||
| dropout = 0.1 | |||||
| word_vec_dim = 384 | |||||
| encoder_n_layer = 6 | |||||
| encoder_head = 2 | |||||
| encoder_conv1d_filter_size = 1536 | |||||
| max_sep_len = 2048 | |||||
| encoder_output_size = 384 | |||||
| decoder_n_layer = 6 | |||||
| decoder_head = 2 | |||||
| decoder_conv1d_filter_size = 1536 | |||||
| decoder_output_size = 384 | |||||
| fft_conv1d_kernel = 3 | |||||
| fft_conv1d_padding = 1 | |||||
| duration_predictor_filter_size = 256 | |||||
| duration_predictor_kernel_size = 3 | |||||
| dropout = 0.1 | |||||
| # Train | |||||
| alignment_path = "./alignments" | |||||
| checkpoint_path = "./model_new" | |||||
| logger_path = "./logger" | |||||
| mel_ground_truth = "./mels" | |||||
| batch_size = 64 | |||||
| epochs = 1000 | |||||
| n_warm_up_step = 4000 | |||||
| learning_rate = 1e-3 | |||||
| weight_decay = 1e-6 | |||||
| grad_clip_thresh = 1.0 | |||||
| decay_step = [500000, 1000000, 2000000] | |||||
| save_step = 1000 | |||||
| log_step = 5 | |||||
| clear_Time = 20 | |||||
BIN
FastSpeech/img/model.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1874 | Height: 1057 | Size: 315 KiB |
BIN
FastSpeech/img/model_test.jpg
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1200 | Height: 400 | Size: 137 KiB |
BIN
FastSpeech/img/tacotron2_outputs.jpg
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 1600 | Height: 400 | Size: 129 KiB |
+ 29
- 0
FastSpeech/loss.py
View File
| @ -0,0 +1,29 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| class FastSpeechLoss(nn.Module): | |||||
| """ FastSPeech Loss """ | |||||
| def __init__(self): | |||||
| super(FastSpeechLoss, self).__init__() | |||||
| self.mse_loss = nn.MSELoss() | |||||
| self.l1_loss = nn.L1Loss() | |||||
| def forward(self, mel, mel_postnet, duration_predicted, mel_target, duration_predictor_target): | |||||
| mel_target.requires_grad = False | |||||
| mel_loss = self.mse_loss(mel, mel_target) | |||||
| mel_postnet_loss = self.mse_loss(mel_postnet, mel_target) | |||||
| duration_predictor_target.requires_grad = False | |||||
| # duration_predictor_target = duration_predictor_target + 1 | |||||
| # duration_predictor_target = torch.log( | |||||
| # duration_predictor_target.float()) | |||||
| # print(duration_predictor_target) | |||||
| # print(duration_predicted) | |||||
| duration_predictor_loss = self.l1_loss( | |||||
| duration_predicted, duration_predictor_target.float()) | |||||
| return mel_loss, mel_postnet_loss, duration_predictor_loss | |||||
+ 404
- 0
FastSpeech/modules.py
View File
| @ -0,0 +1,404 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| from collections import OrderedDict | |||||
| import numpy as np | |||||
| import copy | |||||
| import math | |||||
| import hparams as hp | |||||
| import utils | |||||
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') | |||||
| def get_sinusoid_encoding_table(n_position, d_hid, padding_idx=None): | |||||
| ''' Sinusoid position encoding table ''' | |||||
| def cal_angle(position, hid_idx): | |||||
| return position / np.power(10000, 2 * (hid_idx // 2) / d_hid) | |||||
| def get_posi_angle_vec(position): | |||||
| return [cal_angle(position, hid_j) for hid_j in range(d_hid)] | |||||
| sinusoid_table = np.array([get_posi_angle_vec(pos_i) | |||||
| for pos_i in range(n_position)]) | |||||
| sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i | |||||
| sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 | |||||
| if padding_idx is not None: | |||||
| # zero vector for padding dimension | |||||
| sinusoid_table[padding_idx] = 0. | |||||
| return torch.FloatTensor(sinusoid_table) | |||||
| def clones(module, N): | |||||
| return nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) | |||||
| class LengthRegulator(nn.Module): | |||||
| """ Length Regulator """ | |||||
| def __init__(self): | |||||
| super(LengthRegulator, self).__init__() | |||||
| self.duration_predictor = DurationPredictor() | |||||
| def LR(self, x, duration_predictor_output, alpha=1.0, mel_max_length=None): | |||||
| output = list() | |||||
| for batch, expand_target in zip(x, duration_predictor_output): | |||||
| output.append(self.expand(batch, expand_target, alpha)) | |||||
| if mel_max_length: | |||||
| output = utils.pad(output, mel_max_length) | |||||
| else: | |||||
| output = utils.pad(output) | |||||
| return output | |||||
| def expand(self, batch, predicted, alpha): | |||||
| out = list() | |||||
| for i, vec in enumerate(batch): | |||||
| expand_size = predicted[i].item() | |||||
| out.append(vec.expand(int(expand_size*alpha), -1)) | |||||
| out = torch.cat(out, 0) | |||||
| return out | |||||
| def rounding(self, num): | |||||
| if num - int(num) >= 0.5: | |||||
| return int(num) + 1 | |||||
| else: | |||||
| return int(num) | |||||
| def forward(self, x, alpha=1.0, target=None, mel_max_length=None): | |||||
| duration_predictor_output = self.duration_predictor(x) | |||||
| if self.training: | |||||
| output = self.LR(x, target, mel_max_length=mel_max_length) | |||||
| return output, duration_predictor_output | |||||
| else: | |||||
| for idx, ele in enumerate(duration_predictor_output[0]): | |||||
| duration_predictor_output[0][idx] = self.rounding(ele) | |||||
| output = self.LR(x, duration_predictor_output, alpha) | |||||
| mel_pos = torch.stack( | |||||
| [torch.Tensor([i+1 for i in range(output.size(1))])]).long().to(device) | |||||
| return output, mel_pos | |||||
| class DurationPredictor(nn.Module): | |||||
| """ Duration Predictor """ | |||||
| def __init__(self): | |||||
| super(DurationPredictor, self).__init__() | |||||
| self.input_size = hp.d_model | |||||
| self.filter_size = hp.duration_predictor_filter_size | |||||
| self.kernel = hp.duration_predictor_kernel_size | |||||
| self.conv_output_size = hp.duration_predictor_filter_size | |||||
| self.dropout = hp.dropout | |||||
| self.conv_layer = nn.Sequential(OrderedDict([ | |||||
| ("conv1d_1", Conv(self.input_size, | |||||
| self.filter_size, | |||||
| kernel_size=self.kernel, | |||||
| padding=1)), | |||||
| ("layer_norm_1", nn.LayerNorm(self.filter_size)), | |||||
| ("relu_1", nn.ReLU()), | |||||
| ("dropout_1", nn.Dropout(self.dropout)), | |||||
| ("conv1d_2", Conv(self.filter_size, | |||||
| self.filter_size, | |||||
| kernel_size=self.kernel, | |||||
| padding=1)), | |||||
| ("layer_norm_2", nn.LayerNorm(self.filter_size)), | |||||
| ("relu_2", nn.ReLU()), | |||||
| ("dropout_2", nn.Dropout(self.dropout)) | |||||
| ])) | |||||
| self.linear_layer = Linear(self.conv_output_size, 1) | |||||
| self.relu = nn.ReLU() | |||||
| def forward(self, encoder_output): | |||||
| out = self.conv_layer(encoder_output) | |||||
| out = self.linear_layer(out) | |||||
| out = self.relu(out) | |||||
| out = out.squeeze() | |||||
| if not self.training: | |||||
| out = out.unsqueeze(0) | |||||
| return out | |||||
| class Conv(nn.Module): | |||||
| """ | |||||
| Convolution Module | |||||
| """ | |||||
| def __init__(self, | |||||
| in_channels, | |||||
| out_channels, | |||||
| kernel_size=1, | |||||
| stride=1, | |||||
| padding=0, | |||||
| dilation=1, | |||||
| bias=True, | |||||
| w_init='linear'): | |||||
| """ | |||||
| :param in_channels: dimension of input | |||||
| :param out_channels: dimension of output | |||||
| :param kernel_size: size of kernel | |||||
| :param stride: size of stride | |||||
| :param padding: size of padding | |||||
| :param dilation: dilation rate | |||||
| :param bias: boolean. if True, bias is included. | |||||
| :param w_init: str. weight inits with xavier initialization. | |||||
| """ | |||||
| super(Conv, self).__init__() | |||||
| self.conv = nn.Conv1d(in_channels, | |||||
| out_channels, | |||||
| kernel_size=kernel_size, | |||||
| stride=stride, | |||||
| padding=padding, | |||||
| dilation=dilation, | |||||
| bias=bias) | |||||
| nn.init.xavier_uniform_( | |||||
| self.conv.weight, gain=nn.init.calculate_gain(w_init)) | |||||
| def forward(self, x): | |||||
| x = x.contiguous().transpose(1, 2) | |||||
| x = self.conv(x) | |||||
| x = x.contiguous().transpose(1, 2) | |||||
| return x | |||||
| class Linear(nn.Module): | |||||
| """ | |||||
| Linear Module | |||||
| """ | |||||
| def __init__(self, in_dim, out_dim, bias=True, w_init='linear'): | |||||
| """ | |||||
| :param in_dim: dimension of input | |||||
| :param out_dim: dimension of output | |||||
| :param bias: boolean. if True, bias is included. | |||||
| :param w_init: str. weight inits with xavier initialization. | |||||
| """ | |||||
| super(Linear, self).__init__() | |||||
| self.linear_layer = nn.Linear(in_dim, out_dim, bias=bias) | |||||
| nn.init.xavier_uniform_( | |||||
| self.linear_layer.weight, | |||||
| gain=nn.init.calculate_gain(w_init)) | |||||
| def forward(self, x): | |||||
| return self.linear_layer(x) | |||||
| class FFN(nn.Module): | |||||
| """ | |||||
| Positionwise Feed-Forward Network | |||||
| """ | |||||
| def __init__(self, num_hidden): | |||||
| """ | |||||
| :param num_hidden: dimension of hidden | |||||
| """ | |||||
| super(FFN, self).__init__() | |||||
| self.w_1 = Conv(num_hidden, num_hidden * 4, | |||||
| kernel_size=3, padding=1, w_init='relu') | |||||
| self.w_2 = Conv(num_hidden * 4, num_hidden, kernel_size=3, padding=1) | |||||
| self.dropout = nn.Dropout(p=0.1) | |||||
| self.layer_norm = nn.LayerNorm(num_hidden) | |||||
| def forward(self, input_): | |||||
| # FFN Network | |||||
| x = input_ | |||||
| x = self.w_2(torch.relu(self.w_1(x))) | |||||
| # residual connection | |||||
| x = x + input_ | |||||
| # dropout | |||||
| x = self.dropout(x) | |||||
| # layer normalization | |||||
| x = self.layer_norm(x) | |||||
| return x | |||||
| class MultiheadAttention(nn.Module): | |||||
| """ | |||||
| Multihead attention mechanism (dot attention) | |||||
| """ | |||||
| def __init__(self, num_hidden_k): | |||||
| """ | |||||
| :param num_hidden_k: dimension of hidden | |||||
| """ | |||||
| super(MultiheadAttention, self).__init__() | |||||
| self.num_hidden_k = num_hidden_k | |||||
| self.attn_dropout = nn.Dropout(p=0.1) | |||||
| def forward(self, key, value, query, mask=None, query_mask=None): | |||||
| # Get attention score | |||||
| attn = torch.bmm(query, key.transpose(1, 2)) | |||||
| attn = attn / math.sqrt(self.num_hidden_k) | |||||
| # Masking to ignore padding (key side) | |||||
| if mask is not None: | |||||
| attn = attn.masked_fill(mask, -2 ** 32 + 1) | |||||
| attn = torch.softmax(attn, dim=-1) | |||||
| else: | |||||
| attn = torch.softmax(attn, dim=-1) | |||||
| # Masking to ignore padding (query side) | |||||
| if query_mask is not None: | |||||
| attn = attn * query_mask | |||||
| # Dropout | |||||
| attn = self.attn_dropout(attn) | |||||
| # Get Context Vector | |||||
| result = torch.bmm(attn, value) | |||||
| return result, attn | |||||
| class Attention(nn.Module): | |||||
| """ | |||||
| Attention Network | |||||
| """ | |||||
| def __init__(self, num_hidden, h=2): | |||||
| """ | |||||
| :param num_hidden: dimension of hidden | |||||
| :param h: num of heads | |||||
| """ | |||||
| super(Attention, self).__init__() | |||||
| self.num_hidden = num_hidden | |||||
| self.num_hidden_per_attn = num_hidden // h | |||||
| self.h = h | |||||
| self.key = Linear(num_hidden, num_hidden, bias=False) | |||||
| self.value = Linear(num_hidden, num_hidden, bias=False) | |||||
| self.query = Linear(num_hidden, num_hidden, bias=False) | |||||
| self.multihead = MultiheadAttention(self.num_hidden_per_attn) | |||||
| self.residual_dropout = nn.Dropout(p=0.1) | |||||
| self.final_linear = Linear(num_hidden * 2, num_hidden) | |||||
| self.layer_norm_1 = nn.LayerNorm(num_hidden) | |||||
| def forward(self, memory, decoder_input, mask=None, query_mask=None): | |||||
| batch_size = memory.size(0) | |||||
| seq_k = memory.size(1) | |||||
| seq_q = decoder_input.size(1) | |||||
| # Repeat masks h times | |||||
| if query_mask is not None: | |||||
| query_mask = query_mask.unsqueeze(-1).repeat(1, 1, seq_k) | |||||
| query_mask = query_mask.repeat(self.h, 1, 1) | |||||
| if mask is not None: | |||||
| mask = mask.repeat(self.h, 1, 1) | |||||
| # Make multihead | |||||
| key = self.key(memory).view(batch_size, | |||||
| seq_k, | |||||
| self.h, | |||||
| self.num_hidden_per_attn) | |||||
| value = self.value(memory).view(batch_size, | |||||
| seq_k, | |||||
| self.h, | |||||
| self.num_hidden_per_attn) | |||||
| query = self.query(decoder_input).view(batch_size, | |||||
| seq_q, | |||||
| self.h, | |||||
| self.num_hidden_per_attn) | |||||
| key = key.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| seq_k, | |||||
| self.num_hidden_per_attn) | |||||
| value = value.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| seq_k, | |||||
| self.num_hidden_per_attn) | |||||
| query = query.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| seq_q, | |||||
| self.num_hidden_per_attn) | |||||
| # Get context vector | |||||
| result, attns = self.multihead( | |||||
| key, value, query, mask=mask, query_mask=query_mask) | |||||
| # Concatenate all multihead context vector | |||||
| result = result.view(self.h, batch_size, seq_q, | |||||
| self.num_hidden_per_attn) | |||||
| result = result.permute(1, 2, 0, 3).contiguous().view( | |||||
| batch_size, seq_q, -1) | |||||
| # Concatenate context vector with input (most important) | |||||
| result = torch.cat([decoder_input, result], dim=-1) | |||||
| # Final linear | |||||
| result = self.final_linear(result) | |||||
| # Residual dropout & connection | |||||
| result = self.residual_dropout(result) | |||||
| result = result + decoder_input | |||||
| # Layer normalization | |||||
| result = self.layer_norm_1(result) | |||||
| return result, attns | |||||
| class FFTBlock(torch.nn.Module): | |||||
| """FFT Block""" | |||||
| def __init__(self, | |||||
| d_model, | |||||
| n_head=hp.Head): | |||||
| super(FFTBlock, self).__init__() | |||||
| self.slf_attn = clones(Attention(d_model), hp.N) | |||||
| self.pos_ffn = clones(FFN(d_model), hp.N) | |||||
| self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(1024, | |||||
| d_model, | |||||
| padding_idx=0), freeze=True) | |||||
| def forward(self, x, pos, return_attns=False): | |||||
| # Get character mask | |||||
| if self.training: | |||||
| c_mask = pos.ne(0).type(torch.float) | |||||
| mask = pos.eq(0).unsqueeze(1).repeat(1, x.size(1), 1) | |||||
| else: | |||||
| c_mask, mask = None, None | |||||
| # Get positional embedding, apply alpha and add | |||||
| pos = self.pos_emb(pos) | |||||
| x = x + pos | |||||
| # Attention encoder-encoder | |||||
| attns = list() | |||||
| for slf_attn, ffn in zip(self.slf_attn, self.pos_ffn): | |||||
| x, attn = slf_attn(x, x, mask=mask, query_mask=c_mask) | |||||
| x = ffn(x) | |||||
| attns.append(attn) | |||||
| return x, attns | |||||
+ 44
- 0
FastSpeech/optimizer.py
View File
| @ -0,0 +1,44 @@ | |||||
| import numpy as np | |||||
| class ScheduledOptim(): | |||||
| ''' A simple wrapper class for learning rate scheduling ''' | |||||
| def __init__(self, optimizer, d_model, n_warmup_steps, current_steps): | |||||
| self._optimizer = optimizer | |||||
| self.n_warmup_steps = n_warmup_steps | |||||
| self.n_current_steps = current_steps | |||||
| self.init_lr = np.power(d_model, -0.5) | |||||
| def step_and_update_lr_frozen(self, learning_rate_frozen): | |||||
| for param_group in self._optimizer.param_groups: | |||||
| param_group['lr'] = learning_rate_frozen | |||||
| self._optimizer.step() | |||||
| def step_and_update_lr(self): | |||||
| self._update_learning_rate() | |||||
| self._optimizer.step() | |||||
| def get_learning_rate(self): | |||||
| learning_rate = 0.0 | |||||
| for param_group in self._optimizer.param_groups: | |||||
| learning_rate = param_group['lr'] | |||||
| return learning_rate | |||||
| def zero_grad(self): | |||||
| # print(self.init_lr) | |||||
| self._optimizer.zero_grad() | |||||
| def _get_lr_scale(self): | |||||
| return np.min([ | |||||
| np.power(self.n_current_steps, -0.5), | |||||
| np.power(self.n_warmup_steps, -1.5) * self.n_current_steps]) | |||||
| def _update_learning_rate(self): | |||||
| ''' Learning rate scheduling per step ''' | |||||
| self.n_current_steps += 1 | |||||
| lr = self.init_lr * self._get_lr_scale() | |||||
| for param_group in self._optimizer.param_groups: | |||||
| param_group['lr'] = lr | |||||
+ 61
- 0
FastSpeech/preprocess.py
View File
| @ -0,0 +1,61 @@ | |||||
| import torch | |||||
| import numpy as np | |||||
| import shutil | |||||
| import os | |||||
| from utils import load_data, get_Tacotron2, get_WaveGlow | |||||
| from utils import process_text, load_data | |||||
| from data import ljspeech | |||||
| import hparams as hp | |||||
| import waveglow | |||||
| import audio as Audio | |||||
| def preprocess_ljspeech(filename): | |||||
| in_dir = filename | |||||
| out_dir = hp.mel_ground_truth | |||||
| if not os.path.exists(out_dir): | |||||
| os.makedirs(out_dir, exist_ok=True) | |||||
| metadata = ljspeech.build_from_path(in_dir, out_dir) | |||||
| write_metadata(metadata, out_dir) | |||||
| shutil.move(os.path.join(hp.mel_ground_truth, "train.txt"), | |||||
| os.path.join("data", "train.txt")) | |||||
| def write_metadata(metadata, out_dir): | |||||
| with open(os.path.join(out_dir, 'train.txt'), 'w', encoding='utf-8') as f: | |||||
| for m in metadata: | |||||
| f.write(m + '\n') | |||||
| def main(): | |||||
| path = os.path.join("data", "LJSpeech-1.1") | |||||
| preprocess_ljspeech(path) | |||||
| text_path = os.path.join("data", "train.txt") | |||||
| texts = process_text(text_path) | |||||
| if not os.path.exists(hp.alignment_path): | |||||
| os.mkdir(hp.alignment_path) | |||||
| else: | |||||
| return | |||||
| tacotron2 = get_Tacotron2() | |||||
| num = 0 | |||||
| for ind, text in enumerate(texts[num:]): | |||||
| print(ind) | |||||
| character = text[0:len(text)-1] | |||||
| mel_gt_name = os.path.join( | |||||
| hp.mel_ground_truth, "ljspeech-mel-%05d.npy" % (ind+num+1)) | |||||
| mel_gt_target = np.load(mel_gt_name) | |||||
| _, _, D = load_data(character, mel_gt_target, tacotron2) | |||||
| np.save(os.path.join(hp.alignment_path, str( | |||||
| ind+num) + ".npy"), D, allow_pickle=False) | |||||
| if __name__ == "__main__": | |||||
| main() | |||||
BIN
FastSpeech/results/0.wav
View File
BIN
FastSpeech/results/1.wav
View File
BIN
FastSpeech/results/2.wav
View File
+ 74
- 0
FastSpeech/synthesis.py
View File
| @ -0,0 +1,74 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import matplotlib | |||||
| import matplotlib.pyplot as plt | |||||
| import numpy as np | |||||
| import time | |||||
| import os | |||||
| from fastspeech import FastSpeech | |||||
| from text import text_to_sequence | |||||
| import hparams as hp | |||||
| import utils | |||||
| import audio as Audio | |||||
| import glow | |||||
| import waveglow | |||||
| device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') | |||||
| def get_FastSpeech(num): | |||||
| checkpoint_path = "checkpoint_" + str(num) + ".pth.tar" | |||||
| model = nn.DataParallel(FastSpeech()).to(device) | |||||
| model.load_state_dict(torch.load(os.path.join( | |||||
| hp.checkpoint_path, checkpoint_path))['model']) | |||||
| model.eval() | |||||
| return model | |||||
| def synthesis(model, text, alpha=1.0): | |||||
| text = np.array(text_to_sequence(text, hp.text_cleaners)) | |||||
| text = np.stack([text]) | |||||
| src_pos = np.array([i+1 for i in range(text.shape[1])]) | |||||
| src_pos = np.stack([src_pos]) | |||||
| with torch.no_grad(): | |||||
| sequence = torch.autograd.Variable( | |||||
| torch.from_numpy(text)).cuda().long() | |||||
| src_pos = torch.autograd.Variable( | |||||
| torch.from_numpy(src_pos)).cuda().long() | |||||
| mel, mel_postnet = model.module.forward(sequence, src_pos, alpha=alpha) | |||||
| return mel[0].cpu().transpose(0, 1), \ | |||||
| mel_postnet[0].cpu().transpose(0, 1), \ | |||||
| mel.transpose(1, 2), \ | |||||
| mel_postnet.transpose(1, 2) | |||||
| if __name__ == "__main__": | |||||
| # Test | |||||
| num = 112000 | |||||
| alpha = 1.0 | |||||
| model = get_FastSpeech(num) | |||||
| words = "Let’s go out to the airport. The plane landed ten minutes ago." | |||||
| mel, mel_postnet, mel_torch, mel_postnet_torch = synthesis( | |||||
| model, words, alpha=alpha) | |||||
| if not os.path.exists("results"): | |||||
| os.mkdir("results") | |||||
| Audio.tools.inv_mel_spec(mel_postnet, os.path.join( | |||||
| "results", words + "_" + str(num) + "_griffin_lim.wav")) | |||||
| wave_glow = utils.get_WaveGlow() | |||||
| waveglow.inference.inference(mel_postnet_torch, wave_glow, os.path.join( | |||||
| "results", words + "_" + str(num) + "_waveglow.wav")) | |||||
| tacotron2 = utils.get_Tacotron2() | |||||
| mel_tac2, _, _ = utils.load_data_from_tacotron2(words, tacotron2) | |||||
| waveglow.inference.inference(torch.stack([torch.from_numpy( | |||||
| mel_tac2).cuda()]), wave_glow, os.path.join("results", "tacotron2.wav")) | |||||
| utils.plot_data([mel.numpy(), mel_postnet.numpy(), mel_tac2]) | |||||
+ 3
- 0
FastSpeech/tacotron2/__init__.py
View File
| @ -0,0 +1,3 @@ | |||||
| import tacotron2.hparams | |||||
| import tacotron2.model | |||||
| import tacotron2.layers | |||||
+ 92
- 0
FastSpeech/tacotron2/hparams.py
View File
| @ -0,0 +1,92 @@ | |||||
| from text import symbols | |||||
| class Hparams: | |||||
| """ hyper parameters """ | |||||
| def __init__(self): | |||||
| ################################ | |||||
| # Experiment Parameters # | |||||
| ################################ | |||||
| self.epochs = 500 | |||||
| self.iters_per_checkpoint = 1000 | |||||
| self.seed = 1234 | |||||
| self.dynamic_loss_scaling = True | |||||
| self.fp16_run = False | |||||
| self.distributed_run = False | |||||
| self.dist_backend = "nccl" | |||||
| self.dist_url = "tcp://localhost:54321" | |||||
| self.cudnn_enabled = True | |||||
| self.cudnn_benchmark = False | |||||
| self.ignore_layers = ['embedding.weight'] | |||||
| ################################ | |||||
| # Data Parameters # | |||||
| ################################ | |||||
| self.load_mel_from_disk = False | |||||
| self.training_files = 'filelists/ljs_audio_text_train_filelist.txt' | |||||
| self.validation_files = 'filelists/ljs_audio_text_val_filelist.txt' | |||||
| self.text_cleaners = ['english_cleaners'] | |||||
| ################################ | |||||
| # Audio Parameters # | |||||
| ################################ | |||||
| self.max_wav_value = 32768.0 | |||||
| self.sampling_rate = 22050 | |||||
| self.filter_length = 1024 | |||||
| self.hop_length = 256 | |||||
| self.win_length = 1024 | |||||
| self.n_mel_channels = 80 | |||||
| self.mel_fmin = 0.0 | |||||
| self.mel_fmax = 8000.0 | |||||
| ################################ | |||||
| # Model Parameters # | |||||
| ################################ | |||||
| self.n_symbols = len(symbols) | |||||
| self.symbols_embedding_dim = 512 | |||||
| # Encoder parameters | |||||
| self.encoder_kernel_size = 5 | |||||
| self.encoder_n_convolutions = 3 | |||||
| self.encoder_embedding_dim = 512 | |||||
| # Decoder parameters | |||||
| self.n_frames_per_step = 1 # currently only 1 is supported | |||||
| self.decoder_rnn_dim = 1024 | |||||
| self.prenet_dim = 256 | |||||
| self.max_decoder_steps = 1000 | |||||
| self.gate_threshold = 0.5 | |||||
| self.p_attention_dropout = 0.1 | |||||
| self.p_decoder_dropout = 0.1 | |||||
| # Attention parameters | |||||
| self.attention_rnn_dim = 1024 | |||||
| self.attention_dim = 128 | |||||
| # Location Layer parameters | |||||
| self.attention_location_n_filters = 32 | |||||
| self.attention_location_kernel_size = 31 | |||||
| # Mel-post processing network parameters | |||||
| self.postnet_embedding_dim = 512 | |||||
| self.postnet_kernel_size = 5 | |||||
| self.postnet_n_convolutions = 5 | |||||
| ################################ | |||||
| # Optimization Hyperparameters # | |||||
| ################################ | |||||
| self.use_saved_learning_rate = False | |||||
| self.learning_rate = 1e-3 | |||||
| self.weight_decay = 1e-6 | |||||
| self.grad_clip_thresh = 1.0 | |||||
| self.batch_size = 64 | |||||
| self.mask_padding = True # set model's padded outputs to padded values | |||||
| def return_self(self): | |||||
| return self | |||||
| def create_hparams(): | |||||
| hparams = Hparams() | |||||
| return hparams.return_self() | |||||
+ 36
- 0
FastSpeech/tacotron2/layers.py
View File
| @ -0,0 +1,36 @@ | |||||
| import torch | |||||
| from librosa.filters import mel as librosa_mel_fn | |||||
| class LinearNorm(torch.nn.Module): | |||||
| def __init__(self, in_dim, out_dim, bias=True, w_init_gain='linear'): | |||||
| super(LinearNorm, self).__init__() | |||||
| self.linear_layer = torch.nn.Linear(in_dim, out_dim, bias=bias) | |||||
| torch.nn.init.xavier_uniform_( | |||||
| self.linear_layer.weight, | |||||
| gain=torch.nn.init.calculate_gain(w_init_gain)) | |||||
| def forward(self, x): | |||||
| return self.linear_layer(x) | |||||
| class ConvNorm(torch.nn.Module): | |||||
| def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, | |||||
| padding=None, dilation=1, bias=True, w_init_gain='linear'): | |||||
| super(ConvNorm, self).__init__() | |||||
| if padding is None: | |||||
| assert(kernel_size % 2 == 1) | |||||
| padding = int(dilation * (kernel_size - 1) / 2) | |||||
| self.conv = torch.nn.Conv1d(in_channels, out_channels, | |||||
| kernel_size=kernel_size, stride=stride, | |||||
| padding=padding, dilation=dilation, | |||||
| bias=bias) | |||||
| torch.nn.init.xavier_uniform_( | |||||
| self.conv.weight, gain=torch.nn.init.calculate_gain(w_init_gain)) | |||||
| def forward(self, signal): | |||||
| conv_signal = self.conv(signal) | |||||
| return conv_signal | |||||
+ 533
- 0
FastSpeech/tacotron2/model.py
View File
| @ -0,0 +1,533 @@ | |||||
| from math import sqrt | |||||
| import torch | |||||
| from torch.autograd import Variable | |||||
| from torch import nn | |||||
| from torch.nn import functional as F | |||||
| from tacotron2.layers import ConvNorm, LinearNorm | |||||
| from tacotron2.utils import to_gpu, get_mask_from_lengths | |||||
| class LocationLayer(nn.Module): | |||||
| def __init__(self, attention_n_filters, attention_kernel_size, | |||||
| attention_dim): | |||||
| super(LocationLayer, self).__init__() | |||||
| padding = int((attention_kernel_size - 1) / 2) | |||||
| self.location_conv = ConvNorm(2, attention_n_filters, | |||||
| kernel_size=attention_kernel_size, | |||||
| padding=padding, bias=False, stride=1, | |||||
| dilation=1) | |||||
| self.location_dense = LinearNorm(attention_n_filters, attention_dim, | |||||
| bias=False, w_init_gain='tanh') | |||||
| def forward(self, attention_weights_cat): | |||||
| processed_attention = self.location_conv(attention_weights_cat) | |||||
| processed_attention = processed_attention.transpose(1, 2) | |||||
| processed_attention = self.location_dense(processed_attention) | |||||
| return processed_attention | |||||
| class Attention(nn.Module): | |||||
| def __init__(self, attention_rnn_dim, embedding_dim, attention_dim, | |||||
| attention_location_n_filters, attention_location_kernel_size): | |||||
| super(Attention, self).__init__() | |||||
| self.query_layer = LinearNorm(attention_rnn_dim, attention_dim, | |||||
| bias=False, w_init_gain='tanh') | |||||
| self.memory_layer = LinearNorm(embedding_dim, attention_dim, bias=False, | |||||
| w_init_gain='tanh') | |||||
| self.v = LinearNorm(attention_dim, 1, bias=False) | |||||
| self.location_layer = LocationLayer(attention_location_n_filters, | |||||
| attention_location_kernel_size, | |||||
| attention_dim) | |||||
| self.score_mask_value = -float("inf") | |||||
| def get_alignment_energies(self, query, processed_memory, | |||||
| attention_weights_cat): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| query: decoder output (batch, n_mel_channels * n_frames_per_step) | |||||
| processed_memory: processed encoder outputs (B, T_in, attention_dim) | |||||
| attention_weights_cat: cumulative and prev. att weights (B, 2, max_time) | |||||
| RETURNS | |||||
| ------- | |||||
| alignment (batch, max_time) | |||||
| """ | |||||
| processed_query = self.query_layer(query.unsqueeze(1)) | |||||
| processed_attention_weights = self.location_layer( | |||||
| attention_weights_cat) | |||||
| energies = self.v(torch.tanh( | |||||
| processed_query + processed_attention_weights + processed_memory)) | |||||
| energies = energies.squeeze(-1) | |||||
| return energies | |||||
| def forward(self, attention_hidden_state, memory, processed_memory, | |||||
| attention_weights_cat, mask): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| attention_hidden_state: attention rnn last output | |||||
| memory: encoder outputs | |||||
| processed_memory: processed encoder outputs | |||||
| attention_weights_cat: previous and cummulative attention weights | |||||
| mask: binary mask for padded data | |||||
| """ | |||||
| alignment = self.get_alignment_energies( | |||||
| attention_hidden_state, processed_memory, attention_weights_cat) | |||||
| if mask is not None: | |||||
| alignment.data.masked_fill_(mask, self.score_mask_value) | |||||
| attention_weights = F.softmax(alignment, dim=1) | |||||
| attention_context = torch.bmm(attention_weights.unsqueeze(1), memory) | |||||
| attention_context = attention_context.squeeze(1) | |||||
| return attention_context, attention_weights | |||||
| class Prenet(nn.Module): | |||||
| def __init__(self, in_dim, sizes): | |||||
| super(Prenet, self).__init__() | |||||
| in_sizes = [in_dim] + sizes[:-1] | |||||
| self.layers = nn.ModuleList( | |||||
| [LinearNorm(in_size, out_size, bias=False) | |||||
| for (in_size, out_size) in zip(in_sizes, sizes)]) | |||||
| def forward(self, x): | |||||
| for linear in self.layers: | |||||
| x = F.dropout(F.relu(linear(x)), p=0.5, training=True) | |||||
| return x | |||||
| class Postnet(nn.Module): | |||||
| """Postnet | |||||
| - Five 1-d convolution with 512 channels and kernel size 5 | |||||
| """ | |||||
| def __init__(self, hparams): | |||||
| super(Postnet, self).__init__() | |||||
| self.convolutions = nn.ModuleList() | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(hparams.n_mel_channels, hparams.postnet_embedding_dim, | |||||
| kernel_size=hparams.postnet_kernel_size, stride=1, | |||||
| padding=int((hparams.postnet_kernel_size - 1) / 2), | |||||
| dilation=1, w_init_gain='tanh'), | |||||
| nn.BatchNorm1d(hparams.postnet_embedding_dim)) | |||||
| ) | |||||
| for i in range(1, hparams.postnet_n_convolutions - 1): | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(hparams.postnet_embedding_dim, | |||||
| hparams.postnet_embedding_dim, | |||||
| kernel_size=hparams.postnet_kernel_size, stride=1, | |||||
| padding=int( | |||||
| (hparams.postnet_kernel_size - 1) / 2), | |||||
| dilation=1, w_init_gain='tanh'), | |||||
| nn.BatchNorm1d(hparams.postnet_embedding_dim)) | |||||
| ) | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(hparams.postnet_embedding_dim, hparams.n_mel_channels, | |||||
| kernel_size=hparams.postnet_kernel_size, stride=1, | |||||
| padding=int((hparams.postnet_kernel_size - 1) / 2), | |||||
| dilation=1, w_init_gain='linear'), | |||||
| nn.BatchNorm1d(hparams.n_mel_channels)) | |||||
| ) | |||||
| def forward(self, x): | |||||
| for i in range(len(self.convolutions) - 1): | |||||
| x = F.dropout(torch.tanh( | |||||
| self.convolutions[i](x)), 0.5, self.training) | |||||
| x = F.dropout(self.convolutions[-1](x), 0.5, self.training) | |||||
| return x | |||||
| class Encoder(nn.Module): | |||||
| """Encoder module: | |||||
| - Three 1-d convolution banks | |||||
| - Bidirectional LSTM | |||||
| """ | |||||
| def __init__(self, hparams): | |||||
| super(Encoder, self).__init__() | |||||
| convolutions = [] | |||||
| for _ in range(hparams.encoder_n_convolutions): | |||||
| conv_layer = nn.Sequential( | |||||
| ConvNorm(hparams.encoder_embedding_dim, | |||||
| hparams.encoder_embedding_dim, | |||||
| kernel_size=hparams.encoder_kernel_size, stride=1, | |||||
| padding=int((hparams.encoder_kernel_size - 1) / 2), | |||||
| dilation=1, w_init_gain='relu'), | |||||
| nn.BatchNorm1d(hparams.encoder_embedding_dim)) | |||||
| convolutions.append(conv_layer) | |||||
| self.convolutions = nn.ModuleList(convolutions) | |||||
| self.lstm = nn.LSTM(hparams.encoder_embedding_dim, | |||||
| int(hparams.encoder_embedding_dim / 2), 1, | |||||
| batch_first=True, bidirectional=True) | |||||
| def forward(self, x, input_lengths): | |||||
| for conv in self.convolutions: | |||||
| x = F.dropout(F.relu(conv(x)), 0.5, self.training) | |||||
| x = x.transpose(1, 2) | |||||
| # pytorch tensor are not reversible, hence the conversion | |||||
| input_lengths = input_lengths.cpu().numpy() | |||||
| x = nn.utils.rnn.pack_padded_sequence( | |||||
| x, input_lengths, batch_first=True) | |||||
| self.lstm.flatten_parameters() | |||||
| outputs, _ = self.lstm(x) | |||||
| outputs, _ = nn.utils.rnn.pad_packed_sequence( | |||||
| outputs, batch_first=True) | |||||
| return outputs | |||||
| def inference(self, x): | |||||
| for conv in self.convolutions: | |||||
| x = F.dropout(F.relu(conv(x)), 0.5, self.training) | |||||
| x = x.transpose(1, 2) | |||||
| self.lstm.flatten_parameters() | |||||
| outputs, _ = self.lstm(x) | |||||
| return outputs | |||||
| class Decoder(nn.Module): | |||||
| def __init__(self, hparams): | |||||
| super(Decoder, self).__init__() | |||||
| self.n_mel_channels = hparams.n_mel_channels | |||||
| self.n_frames_per_step = hparams.n_frames_per_step | |||||
| self.encoder_embedding_dim = hparams.encoder_embedding_dim | |||||
| self.attention_rnn_dim = hparams.attention_rnn_dim | |||||
| self.decoder_rnn_dim = hparams.decoder_rnn_dim | |||||
| self.prenet_dim = hparams.prenet_dim | |||||
| self.max_decoder_steps = hparams.max_decoder_steps | |||||
| self.gate_threshold = hparams.gate_threshold | |||||
| self.p_attention_dropout = hparams.p_attention_dropout | |||||
| self.p_decoder_dropout = hparams.p_decoder_dropout | |||||
| self.prenet = Prenet( | |||||
| hparams.n_mel_channels * hparams.n_frames_per_step, | |||||
| [hparams.prenet_dim, hparams.prenet_dim]) | |||||
| self.attention_rnn = nn.LSTMCell( | |||||
| hparams.prenet_dim + hparams.encoder_embedding_dim, | |||||
| hparams.attention_rnn_dim) | |||||
| self.attention_layer = Attention( | |||||
| hparams.attention_rnn_dim, hparams.encoder_embedding_dim, | |||||
| hparams.attention_dim, hparams.attention_location_n_filters, | |||||
| hparams.attention_location_kernel_size) | |||||
| self.decoder_rnn = nn.LSTMCell( | |||||
| hparams.attention_rnn_dim + hparams.encoder_embedding_dim, | |||||
| hparams.decoder_rnn_dim, 1) | |||||
| self.linear_projection = LinearNorm( | |||||
| hparams.decoder_rnn_dim + hparams.encoder_embedding_dim, | |||||
| hparams.n_mel_channels * hparams.n_frames_per_step) | |||||
| self.gate_layer = LinearNorm( | |||||
| hparams.decoder_rnn_dim + hparams.encoder_embedding_dim, 1, | |||||
| bias=True, w_init_gain='sigmoid') | |||||
| def get_go_frame(self, memory): | |||||
| """ Gets all zeros frames to use as first decoder input | |||||
| PARAMS | |||||
| ------ | |||||
| memory: decoder outputs | |||||
| RETURNS | |||||
| ------- | |||||
| decoder_input: all zeros frames | |||||
| """ | |||||
| B = memory.size(0) | |||||
| decoder_input = Variable(memory.data.new( | |||||
| B, self.n_mel_channels * self.n_frames_per_step).zero_()) | |||||
| return decoder_input | |||||
| def initialize_decoder_states(self, memory, mask): | |||||
| """ Initializes attention rnn states, decoder rnn states, attention | |||||
| weights, attention cumulative weights, attention context, stores memory | |||||
| and stores processed memory | |||||
| PARAMS | |||||
| ------ | |||||
| memory: Encoder outputs | |||||
| mask: Mask for padded data if training, expects None for inference | |||||
| """ | |||||
| B = memory.size(0) | |||||
| MAX_TIME = memory.size(1) | |||||
| self.attention_hidden = Variable(memory.data.new( | |||||
| B, self.attention_rnn_dim).zero_()) | |||||
| self.attention_cell = Variable(memory.data.new( | |||||
| B, self.attention_rnn_dim).zero_()) | |||||
| self.decoder_hidden = Variable(memory.data.new( | |||||
| B, self.decoder_rnn_dim).zero_()) | |||||
| self.decoder_cell = Variable(memory.data.new( | |||||
| B, self.decoder_rnn_dim).zero_()) | |||||
| self.attention_weights = Variable(memory.data.new( | |||||
| B, MAX_TIME).zero_()) | |||||
| self.attention_weights_cum = Variable(memory.data.new( | |||||
| B, MAX_TIME).zero_()) | |||||
| self.attention_context = Variable(memory.data.new( | |||||
| B, self.encoder_embedding_dim).zero_()) | |||||
| self.memory = memory | |||||
| self.processed_memory = self.attention_layer.memory_layer(memory) | |||||
| self.mask = mask | |||||
| def parse_decoder_inputs(self, decoder_inputs): | |||||
| """ Prepares decoder inputs, i.e. mel outputs | |||||
| PARAMS | |||||
| ------ | |||||
| decoder_inputs: inputs used for teacher-forced training, i.e. mel-specs | |||||
| RETURNS | |||||
| ------- | |||||
| inputs: processed decoder inputs | |||||
| """ | |||||
| # (B, n_mel_channels, T_out) -> (B, T_out, n_mel_channels) | |||||
| decoder_inputs = decoder_inputs.transpose(1, 2) | |||||
| decoder_inputs = decoder_inputs.view( | |||||
| decoder_inputs.size(0), | |||||
| int(decoder_inputs.size(1)/self.n_frames_per_step), -1) | |||||
| # (B, T_out, n_mel_channels) -> (T_out, B, n_mel_channels) | |||||
| decoder_inputs = decoder_inputs.transpose(0, 1) | |||||
| return decoder_inputs | |||||
| def parse_decoder_outputs(self, mel_outputs, gate_outputs, alignments): | |||||
| """ Prepares decoder outputs for output | |||||
| PARAMS | |||||
| ------ | |||||
| mel_outputs: | |||||
| gate_outputs: gate output energies | |||||
| alignments: | |||||
| RETURNS | |||||
| ------- | |||||
| mel_outputs: | |||||
| gate_outpust: gate output energies | |||||
| alignments: | |||||
| """ | |||||
| # (T_out, B) -> (B, T_out) | |||||
| alignments = torch.stack(alignments).transpose(0, 1) | |||||
| # (T_out, B) -> (B, T_out) | |||||
| gate_outputs = torch.stack(gate_outputs).transpose(0, 1) | |||||
| gate_outputs = gate_outputs.contiguous() | |||||
| # (T_out, B, n_mel_channels) -> (B, T_out, n_mel_channels) | |||||
| mel_outputs = torch.stack(mel_outputs).transpose(0, 1).contiguous() | |||||
| # decouple frames per step | |||||
| mel_outputs = mel_outputs.view( | |||||
| mel_outputs.size(0), -1, self.n_mel_channels) | |||||
| # (B, T_out, n_mel_channels) -> (B, n_mel_channels, T_out) | |||||
| mel_outputs = mel_outputs.transpose(1, 2) | |||||
| return mel_outputs, gate_outputs, alignments | |||||
| def decode(self, decoder_input): | |||||
| """ Decoder step using stored states, attention and memory | |||||
| PARAMS | |||||
| ------ | |||||
| decoder_input: previous mel output | |||||
| RETURNS | |||||
| ------- | |||||
| mel_output: | |||||
| gate_output: gate output energies | |||||
| attention_weights: | |||||
| """ | |||||
| cell_input = torch.cat((decoder_input, self.attention_context), -1) | |||||
| self.attention_hidden, self.attention_cell = self.attention_rnn( | |||||
| cell_input, (self.attention_hidden, self.attention_cell)) | |||||
| self.attention_hidden = F.dropout( | |||||
| self.attention_hidden, self.p_attention_dropout, self.training) | |||||
| attention_weights_cat = torch.cat( | |||||
| (self.attention_weights.unsqueeze(1), | |||||
| self.attention_weights_cum.unsqueeze(1)), dim=1) | |||||
| self.attention_context, self.attention_weights = self.attention_layer( | |||||
| self.attention_hidden, self.memory, self.processed_memory, | |||||
| attention_weights_cat, self.mask) | |||||
| self.attention_weights_cum += self.attention_weights | |||||
| decoder_input = torch.cat( | |||||
| (self.attention_hidden, self.attention_context), -1) | |||||
| self.decoder_hidden, self.decoder_cell = self.decoder_rnn( | |||||
| decoder_input, (self.decoder_hidden, self.decoder_cell)) | |||||
| self.decoder_hidden = F.dropout( | |||||
| self.decoder_hidden, self.p_decoder_dropout, self.training) | |||||
| decoder_hidden_attention_context = torch.cat( | |||||
| (self.decoder_hidden, self.attention_context), dim=1) | |||||
| decoder_output = self.linear_projection( | |||||
| decoder_hidden_attention_context) | |||||
| gate_prediction = self.gate_layer(decoder_hidden_attention_context) | |||||
| return decoder_output, gate_prediction, self.attention_weights | |||||
| def forward(self, memory, decoder_inputs, memory_lengths): | |||||
| """ Decoder forward pass for training | |||||
| PARAMS | |||||
| ------ | |||||
| memory: Encoder outputs | |||||
| decoder_inputs: Decoder inputs for teacher forcing. i.e. mel-specs | |||||
| memory_lengths: Encoder output lengths for attention masking. | |||||
| RETURNS | |||||
| ------- | |||||
| mel_outputs: mel outputs from the decoder | |||||
| gate_outputs: gate outputs from the decoder | |||||
| alignments: sequence of attention weights from the decoder | |||||
| """ | |||||
| decoder_input = self.get_go_frame(memory).unsqueeze(0) | |||||
| decoder_inputs = self.parse_decoder_inputs(decoder_inputs) | |||||
| decoder_inputs = torch.cat((decoder_input, decoder_inputs), dim=0) | |||||
| decoder_inputs = self.prenet(decoder_inputs) | |||||
| self.initialize_decoder_states( | |||||
| memory, mask=~get_mask_from_lengths(memory_lengths)) | |||||
| mel_outputs, gate_outputs, alignments = [], [], [] | |||||
| while len(mel_outputs) < decoder_inputs.size(0) - 1: | |||||
| decoder_input = decoder_inputs[len(mel_outputs)] | |||||
| mel_output, gate_output, attention_weights = self.decode( | |||||
| decoder_input) | |||||
| mel_outputs += [mel_output.squeeze(1)] | |||||
| gate_outputs += [gate_output.squeeze().unsqueeze(0)] | |||||
| alignments += [attention_weights] | |||||
| mel_outputs, gate_outputs, alignments = self.parse_decoder_outputs( | |||||
| mel_outputs, gate_outputs, alignments) | |||||
| return mel_outputs, gate_outputs, alignments | |||||
| def inference(self, memory): | |||||
| """ Decoder inference | |||||
| PARAMS | |||||
| ------ | |||||
| memory: Encoder outputs | |||||
| RETURNS | |||||
| ------- | |||||
| mel_outputs: mel outputs from the decoder | |||||
| gate_outputs: gate outputs from the decoder | |||||
| alignments: sequence of attention weights from the decoder | |||||
| """ | |||||
| decoder_input = self.get_go_frame(memory) | |||||
| self.initialize_decoder_states(memory, mask=None) | |||||
| mel_outputs, gate_outputs, alignments = [], [], [] | |||||
| while True: | |||||
| decoder_input = self.prenet(decoder_input) | |||||
| mel_output, gate_output, alignment = self.decode(decoder_input) | |||||
| mel_outputs += [mel_output.squeeze(1)] | |||||
| gate_outputs += [gate_output] | |||||
| alignments += [alignment] | |||||
| if torch.sigmoid(gate_output.data) > self.gate_threshold: | |||||
| break | |||||
| elif len(mel_outputs) == self.max_decoder_steps: | |||||
| # print("Warning! Reached max decoder steps") | |||||
| break | |||||
| decoder_input = mel_output | |||||
| mel_outputs, gate_outputs, alignments = self.parse_decoder_outputs( | |||||
| mel_outputs, gate_outputs, alignments) | |||||
| return mel_outputs, gate_outputs, alignments | |||||
| class Tacotron2(nn.Module): | |||||
| def __init__(self, hparams): | |||||
| super(Tacotron2, self).__init__() | |||||
| self.mask_padding = hparams.mask_padding | |||||
| self.fp16_run = hparams.fp16_run | |||||
| self.n_mel_channels = hparams.n_mel_channels | |||||
| self.n_frames_per_step = hparams.n_frames_per_step | |||||
| self.embedding = nn.Embedding( | |||||
| hparams.n_symbols, hparams.symbols_embedding_dim) | |||||
| std = sqrt(2.0 / (hparams.n_symbols + hparams.symbols_embedding_dim)) | |||||
| val = sqrt(3.0) * std # uniform bounds for std | |||||
| self.embedding.weight.data.uniform_(-val, val) | |||||
| self.encoder = Encoder(hparams) | |||||
| self.decoder = Decoder(hparams) | |||||
| self.postnet = Postnet(hparams) | |||||
| def parse_batch(self, batch): | |||||
| text_padded, input_lengths, mel_padded, gate_padded, \ | |||||
| output_lengths = batch | |||||
| text_padded = to_gpu(text_padded).long() | |||||
| input_lengths = to_gpu(input_lengths).long() | |||||
| max_len = torch.max(input_lengths.data).item() | |||||
| mel_padded = to_gpu(mel_padded).float() | |||||
| gate_padded = to_gpu(gate_padded).float() | |||||
| output_lengths = to_gpu(output_lengths).long() | |||||
| return ( | |||||
| (text_padded, input_lengths, mel_padded, max_len, output_lengths), | |||||
| (mel_padded, gate_padded)) | |||||
| def parse_output(self, outputs, output_lengths=None): | |||||
| if self.mask_padding and output_lengths is not None: | |||||
| mask = ~get_mask_from_lengths(output_lengths) | |||||
| mask = mask.expand(self.n_mel_channels, mask.size(0), mask.size(1)) | |||||
| mask = mask.permute(1, 0, 2) | |||||
| outputs[0].data.masked_fill_(mask, 0.0) | |||||
| outputs[1].data.masked_fill_(mask, 0.0) | |||||
| outputs[2].data.masked_fill_(mask[:, 0, :], 1e3) # gate energies | |||||
| return outputs | |||||
| def forward(self, inputs): | |||||
| text_inputs, text_lengths, mels, max_len, output_lengths = inputs | |||||
| text_lengths, output_lengths = text_lengths.data, output_lengths.data | |||||
| embedded_inputs = self.embedding(text_inputs).transpose(1, 2) | |||||
| encoder_outputs = self.encoder(embedded_inputs, text_lengths) | |||||
| mel_outputs, gate_outputs, alignments = self.decoder( | |||||
| encoder_outputs, mels, memory_lengths=text_lengths) | |||||
| mel_outputs_postnet = self.postnet(mel_outputs) | |||||
| mel_outputs_postnet = mel_outputs + mel_outputs_postnet | |||||
| return self.parse_output( | |||||
| [mel_outputs, mel_outputs_postnet, gate_outputs, alignments], | |||||
| output_lengths), encoder_outputs | |||||
| def inference(self, inputs): | |||||
| embedded_inputs = self.embedding(inputs).transpose(1, 2) | |||||
| encoder_outputs = self.encoder.inference(embedded_inputs) | |||||
| mel_outputs, gate_outputs, alignments = self.decoder.inference( | |||||
| encoder_outputs) | |||||
| mel_outputs_postnet = self.postnet(mel_outputs) | |||||
| mel_outputs_postnet = mel_outputs + mel_outputs_postnet | |||||
| outputs = self.parse_output( | |||||
| [mel_outputs, mel_outputs_postnet, gate_outputs, alignments]) | |||||
| return outputs, encoder_outputs | |||||
+ 29
- 0
FastSpeech/tacotron2/utils.py
View File
| @ -0,0 +1,29 @@ | |||||
| import numpy as np | |||||
| from scipy.io.wavfile import read | |||||
| import torch | |||||
| def get_mask_from_lengths(lengths): | |||||
| max_len = torch.max(lengths).item() | |||||
| ids = torch.arange(0, max_len, out=torch.cuda.LongTensor(max_len)) | |||||
| mask = (ids < lengths.unsqueeze(1)).byte() | |||||
| return mask | |||||
| def load_wav_to_torch(full_path): | |||||
| sampling_rate, data = read(full_path) | |||||
| return torch.FloatTensor(data.astype(np.float32)), sampling_rate | |||||
| def load_filepaths_and_text(filename, split="|"): | |||||
| with open(filename, encoding='utf-8') as f: | |||||
| filepaths_and_text = [line.strip().split(split) for line in f] | |||||
| return filepaths_and_text | |||||
| def to_gpu(x): | |||||
| x = x.contiguous() | |||||
| if torch.cuda.is_available(): | |||||
| x = x.cuda(non_blocking=True) | |||||
| return torch.autograd.Variable(x) | |||||
+ 75
- 0
FastSpeech/text/__init__.py
View File
| @ -0,0 +1,75 @@ | |||||
| """ from https://github.com/keithito/tacotron """ | |||||
| import re | |||||
| from text import cleaners | |||||
| from text.symbols import symbols | |||||
| # Mappings from symbol to numeric ID and vice versa: | |||||
| _symbol_to_id = {s: i for i, s in enumerate(symbols)} | |||||
| _id_to_symbol = {i: s for i, s in enumerate(symbols)} | |||||
| # Regular expression matching text enclosed in curly braces: | |||||
| _curly_re = re.compile(r'(.*?)\{(.+?)\}(.*)') | |||||
| def text_to_sequence(text, cleaner_names): | |||||
| '''Converts a string of text to a sequence of IDs corresponding to the symbols in the text. | |||||
| The text can optionally have ARPAbet sequences enclosed in curly braces embedded | |||||
| in it. For example, "Turn left on {HH AW1 S S T AH0 N} Street." | |||||
| Args: | |||||
| text: string to convert to a sequence | |||||
| cleaner_names: names of the cleaner functions to run the text through | |||||
| Returns: | |||||
| List of integers corresponding to the symbols in the text | |||||
| ''' | |||||
| sequence = [] | |||||
| # Check for curly braces and treat their contents as ARPAbet: | |||||
| while len(text): | |||||
| m = _curly_re.match(text) | |||||
| if not m: | |||||
| sequence += _symbols_to_sequence(_clean_text(text, cleaner_names)) | |||||
| break | |||||
| sequence += _symbols_to_sequence( | |||||
| _clean_text(m.group(1), cleaner_names)) | |||||
| sequence += _arpabet_to_sequence(m.group(2)) | |||||
| text = m.group(3) | |||||
| return sequence | |||||
| def sequence_to_text(sequence): | |||||
| '''Converts a sequence of IDs back to a string''' | |||||
| result = '' | |||||
| for symbol_id in sequence: | |||||
| if symbol_id in _id_to_symbol: | |||||
| s = _id_to_symbol[symbol_id] | |||||
| # Enclose ARPAbet back in curly braces: | |||||
| if len(s) > 1 and s[0] == '@': | |||||
| s = '{%s}' % s[1:] | |||||
| result += s | |||||
| return result.replace('}{', ' ') | |||||
| def _clean_text(text, cleaner_names): | |||||
| for name in cleaner_names: | |||||
| cleaner = getattr(cleaners, name) | |||||
| if not cleaner: | |||||
| raise Exception('Unknown cleaner: %s' % name) | |||||
| text = cleaner(text) | |||||
| return text | |||||
| def _symbols_to_sequence(symbols): | |||||
| return [_symbol_to_id[s] for s in symbols if _should_keep_symbol(s)] | |||||
| def _arpabet_to_sequence(text): | |||||
| return _symbols_to_sequence(['@' + s for s in text.split()]) | |||||
| def _should_keep_symbol(s): | |||||
| return s in _symbol_to_id and s is not '_' and s is not '~' | |||||
+ 89
- 0
FastSpeech/text/cleaners.py
View File
| @ -0,0 +1,89 @@ | |||||
| """ from https://github.com/keithito/tacotron """ | |||||
| ''' | |||||
| Cleaners are transformations that run over the input text at both training and eval time. | |||||
| Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners" | |||||
| hyperparameter. Some cleaners are English-specific. You'll typically want to use: | |||||
| 1. "english_cleaners" for English text | |||||
| 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using | |||||
| the Unidecode library (https://pypi.python.org/pypi/Unidecode) | |||||
| 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update | |||||
| the symbols in symbols.py to match your data). | |||||
| ''' | |||||
| # Regular expression matching whitespace: | |||||
| import re | |||||
| from unidecode import unidecode | |||||
| from .numbers import normalize_numbers | |||||
| _whitespace_re = re.compile(r'\s+') | |||||
| # List of (regular expression, replacement) pairs for abbreviations: | |||||
| _abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [ | |||||
| ('mrs', 'misess'), | |||||
| ('mr', 'mister'), | |||||
| ('dr', 'doctor'), | |||||
| ('st', 'saint'), | |||||
| ('co', 'company'), | |||||
| ('jr', 'junior'), | |||||
| ('maj', 'major'), | |||||
| ('gen', 'general'), | |||||
| ('drs', 'doctors'), | |||||
| ('rev', 'reverend'), | |||||
| ('lt', 'lieutenant'), | |||||
| ('hon', 'honorable'), | |||||
| ('sgt', 'sergeant'), | |||||
| ('capt', 'captain'), | |||||
| ('esq', 'esquire'), | |||||
| ('ltd', 'limited'), | |||||
| ('col', 'colonel'), | |||||
| ('ft', 'fort'), | |||||
| ]] | |||||
| def expand_abbreviations(text): | |||||
| for regex, replacement in _abbreviations: | |||||
| text = re.sub(regex, replacement, text) | |||||
| return text | |||||
| def expand_numbers(text): | |||||
| return normalize_numbers(text) | |||||
| def lowercase(text): | |||||
| return text.lower() | |||||
| def collapse_whitespace(text): | |||||
| return re.sub(_whitespace_re, ' ', text) | |||||
| def convert_to_ascii(text): | |||||
| return unidecode(text) | |||||
| def basic_cleaners(text): | |||||
| '''Basic pipeline that lowercases and collapses whitespace without transliteration.''' | |||||
| text = lowercase(text) | |||||
| text = collapse_whitespace(text) | |||||
| return text | |||||
| def transliteration_cleaners(text): | |||||
| '''Pipeline for non-English text that transliterates to ASCII.''' | |||||
| text = convert_to_ascii(text) | |||||
| text = lowercase(text) | |||||
| text = collapse_whitespace(text) | |||||
| return text | |||||
| def english_cleaners(text): | |||||
| '''Pipeline for English text, including number and abbreviation expansion.''' | |||||
| text = convert_to_ascii(text) | |||||
| text = lowercase(text) | |||||
| text = expand_numbers(text) | |||||
| text = expand_abbreviations(text) | |||||
| text = collapse_whitespace(text) | |||||
| return text | |||||
+ 64
- 0
FastSpeech/text/cmudict.py
View File
| @ -0,0 +1,64 @@ | |||||
| """ from https://github.com/keithito/tacotron """ | |||||
| import re | |||||
| valid_symbols = [ | |||||
| 'AA', 'AA0', 'AA1', 'AA2', 'AE', 'AE0', 'AE1', 'AE2', 'AH', 'AH0', 'AH1', 'AH2', | |||||
| 'AO', 'AO0', 'AO1', 'AO2', 'AW', 'AW0', 'AW1', 'AW2', 'AY', 'AY0', 'AY1', 'AY2', | |||||
| 'B', 'CH', 'D', 'DH', 'EH', 'EH0', 'EH1', 'EH2', 'ER', 'ER0', 'ER1', 'ER2', 'EY', | |||||
| 'EY0', 'EY1', 'EY2', 'F', 'G', 'HH', 'IH', 'IH0', 'IH1', 'IH2', 'IY', 'IY0', 'IY1', | |||||
| 'IY2', 'JH', 'K', 'L', 'M', 'N', 'NG', 'OW', 'OW0', 'OW1', 'OW2', 'OY', 'OY0', | |||||
| 'OY1', 'OY2', 'P', 'R', 'S', 'SH', 'T', 'TH', 'UH', 'UH0', 'UH1', 'UH2', 'UW', | |||||
| 'UW0', 'UW1', 'UW2', 'V', 'W', 'Y', 'Z', 'ZH' | |||||
| ] | |||||
| _valid_symbol_set = set(valid_symbols) | |||||
| class CMUDict: | |||||
| '''Thin wrapper around CMUDict data. http://www.speech.cs.cmu.edu/cgi-bin/cmudict''' | |||||
| def __init__(self, file_or_path, keep_ambiguous=True): | |||||
| if isinstance(file_or_path, str): | |||||
| with open(file_or_path, encoding='latin-1') as f: | |||||
| entries = _parse_cmudict(f) | |||||
| else: | |||||
| entries = _parse_cmudict(file_or_path) | |||||
| if not keep_ambiguous: | |||||
| entries = {word: pron for word, | |||||
| pron in entries.items() if len(pron) == 1} | |||||
| self._entries = entries | |||||
| def __len__(self): | |||||
| return len(self._entries) | |||||
| def lookup(self, word): | |||||
| '''Returns list of ARPAbet pronunciations of the given word.''' | |||||
| return self._entries.get(word.upper()) | |||||
| _alt_re = re.compile(r'\([0-9]+\)') | |||||
| def _parse_cmudict(file): | |||||
| cmudict = {} | |||||
| for line in file: | |||||
| if len(line) and (line[0] >= 'A' and line[0] <= 'Z' or line[0] == "'"): | |||||
| parts = line.split(' ') | |||||
| word = re.sub(_alt_re, '', parts[0]) | |||||
| pronunciation = _get_pronunciation(parts[1]) | |||||
| if pronunciation: | |||||
| if word in cmudict: | |||||
| cmudict[word].append(pronunciation) | |||||
| else: | |||||
| cmudict[word] = [pronunciation] | |||||
| return cmudict | |||||
| def _get_pronunciation(s): | |||||
| parts = s.strip().split(' ') | |||||
| for part in parts: | |||||
| if part not in _valid_symbol_set: | |||||
| return None | |||||
| return ' '.join(parts) | |||||
+ 71
- 0
FastSpeech/text/numbers.py
View File
| @ -0,0 +1,71 @@ | |||||
| """ from https://github.com/keithito/tacotron """ | |||||
| import inflect | |||||
| import re | |||||
| _inflect = inflect.engine() | |||||
| _comma_number_re = re.compile(r'([0-9][0-9\,]+[0-9])') | |||||
| _decimal_number_re = re.compile(r'([0-9]+\.[0-9]+)') | |||||
| _pounds_re = re.compile(r'£([0-9\,]*[0-9]+)') | |||||
| _dollars_re = re.compile(r'\$([0-9\.\,]*[0-9]+)') | |||||
| _ordinal_re = re.compile(r'[0-9]+(st|nd|rd|th)') | |||||
| _number_re = re.compile(r'[0-9]+') | |||||
| def _remove_commas(m): | |||||
| return m.group(1).replace(',', '') | |||||
| def _expand_decimal_point(m): | |||||
| return m.group(1).replace('.', ' point ') | |||||
| def _expand_dollars(m): | |||||
| match = m.group(1) | |||||
| parts = match.split('.') | |||||
| if len(parts) > 2: | |||||
| return match + ' dollars' # Unexpected format | |||||
| dollars = int(parts[0]) if parts[0] else 0 | |||||
| cents = int(parts[1]) if len(parts) > 1 and parts[1] else 0 | |||||
| if dollars and cents: | |||||
| dollar_unit = 'dollar' if dollars == 1 else 'dollars' | |||||
| cent_unit = 'cent' if cents == 1 else 'cents' | |||||
| return '%s %s, %s %s' % (dollars, dollar_unit, cents, cent_unit) | |||||
| elif dollars: | |||||
| dollar_unit = 'dollar' if dollars == 1 else 'dollars' | |||||
| return '%s %s' % (dollars, dollar_unit) | |||||
| elif cents: | |||||
| cent_unit = 'cent' if cents == 1 else 'cents' | |||||
| return '%s %s' % (cents, cent_unit) | |||||
| else: | |||||
| return 'zero dollars' | |||||
| def _expand_ordinal(m): | |||||
| return _inflect.number_to_words(m.group(0)) | |||||
| def _expand_number(m): | |||||
| num = int(m.group(0)) | |||||
| if num > 1000 and num < 3000: | |||||
| if num == 2000: | |||||
| return 'two thousand' | |||||
| elif num > 2000 and num < 2010: | |||||
| return 'two thousand ' + _inflect.number_to_words(num % 100) | |||||
| elif num % 100 == 0: | |||||
| return _inflect.number_to_words(num // 100) + ' hundred' | |||||
| else: | |||||
| return _inflect.number_to_words(num, andword='', zero='oh', group=2).replace(', ', ' ') | |||||
| else: | |||||
| return _inflect.number_to_words(num, andword='') | |||||
| def normalize_numbers(text): | |||||
| text = re.sub(_comma_number_re, _remove_commas, text) | |||||
| text = re.sub(_pounds_re, r'\1 pounds', text) | |||||
| text = re.sub(_dollars_re, _expand_dollars, text) | |||||
| text = re.sub(_decimal_number_re, _expand_decimal_point, text) | |||||
| text = re.sub(_ordinal_re, _expand_ordinal, text) | |||||
| text = re.sub(_number_re, _expand_number, text) | |||||
| return text | |||||
+ 19
- 0
FastSpeech/text/symbols.py
View File
| @ -0,0 +1,19 @@ | |||||
| """ from https://github.com/keithito/tacotron """ | |||||
| ''' | |||||
| Defines the set of symbols used in text input to the model. | |||||
| The default is a set of ASCII characters that works well for English or text that has been run through Unidecode. For other data, you can modify _characters. See TRAINING_DATA.md for details. ''' | |||||
| from text import cmudict | |||||
| _pad = '_' | |||||
| _punctuation = '!\'(),.:;? ' | |||||
| _special = '-' | |||||
| _letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' | |||||
| # Prepend "@" to ARPAbet symbols to ensure uniqueness (some are the same as uppercase letters): | |||||
| _arpabet = ['@' + s for s in cmudict.valid_symbols] | |||||
| # Export all symbols: | |||||
| symbols = [_pad] + list(_special) + list(_punctuation) + \ | |||||
| list(_letters) + _arpabet | |||||
+ 194
- 0
FastSpeech/train.py
View File
| @ -0,0 +1,194 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| from multiprocessing import cpu_count | |||||
| import numpy as np | |||||
| import argparse | |||||
| import os | |||||
| import time | |||||
| import math | |||||
| from fastspeech import FastSpeech | |||||
| from loss import FastSpeechLoss | |||||
| from dataset import FastSpeechDataset, collate_fn, DataLoader | |||||
| from optimizer import ScheduledOptim | |||||
| import hparams as hp | |||||
| import utils | |||||
| def main(args): | |||||
| # Get device | |||||
| device = torch.device('cuda'if torch.cuda.is_available()else 'cpu') | |||||
| # Define model | |||||
| model = nn.DataParallel(FastSpeech()).to(device) | |||||
| print("Model Has Been Defined") | |||||
| num_param = utils.get_param_num(model) | |||||
| print('Number of FastSpeech Parameters:', num_param) | |||||
| # Get dataset | |||||
| dataset = FastSpeechDataset() | |||||
| # Optimizer and loss | |||||
| optimizer = torch.optim.Adam( | |||||
| model.parameters(), betas=(0.9, 0.98), eps=1e-9) | |||||
| scheduled_optim = ScheduledOptim(optimizer, | |||||
| hp.d_model, | |||||
| hp.n_warm_up_step, | |||||
| args.restore_step) | |||||
| fastspeech_loss = FastSpeechLoss().to(device) | |||||
| print("Defined Optimizer and Loss Function.") | |||||
| # Load checkpoint if exists | |||||
| try: | |||||
| checkpoint = torch.load(os.path.join( | |||||
| hp.checkpoint_path, 'checkpoint_%d.pth.tar' % args.restore_step)) | |||||
| model.load_state_dict(checkpoint['model']) | |||||
| optimizer.load_state_dict(checkpoint['optimizer']) | |||||
| print("\n---Model Restored at Step %d---\n" % args.restore_step) | |||||
| except: | |||||
| print("\n---Start New Training---\n") | |||||
| if not os.path.exists(hp.checkpoint_path): | |||||
| os.mkdir(hp.checkpoint_path) | |||||
| # Init logger | |||||
| if not os.path.exists(hp.logger_path): | |||||
| os.mkdir(hp.logger_path) | |||||
| # Define Some Information | |||||
| Time = np.array([]) | |||||
| Start = time.clock() | |||||
| # Training | |||||
| model = model.train() | |||||
| for epoch in range(hp.epochs): | |||||
| # Get Training Loader | |||||
| training_loader = DataLoader(dataset, | |||||
| batch_size=hp.batch_size**2, | |||||
| shuffle=True, | |||||
| collate_fn=collate_fn, | |||||
| drop_last=True, | |||||
| num_workers=0) | |||||
| total_step = hp.epochs * len(training_loader) * hp.batch_size | |||||
| for i, batchs in enumerate(training_loader): | |||||
| for j, data_of_batch in enumerate(batchs): | |||||
| start_time = time.clock() | |||||
| current_step = i * hp.batch_size + j + args.restore_step + \ | |||||
| epoch * len(training_loader)*hp.batch_size + 1 | |||||
| # Init | |||||
| scheduled_optim.zero_grad() | |||||
| # Get Data | |||||
| character = torch.from_numpy( | |||||
| data_of_batch["text"]).long().to(device) | |||||
| mel_target = torch.from_numpy( | |||||
| data_of_batch["mel_target"]).float().to(device) | |||||
| D = torch.from_numpy(data_of_batch["D"]).int().to(device) | |||||
| mel_pos = torch.from_numpy( | |||||
| data_of_batch["mel_pos"]).long().to(device) | |||||
| src_pos = torch.from_numpy( | |||||
| data_of_batch["src_pos"]).long().to(device) | |||||
| max_mel_len = data_of_batch["mel_max_len"] | |||||
| # Forward | |||||
| mel_output, mel_postnet_output, duration_predictor_output = model(character, | |||||
| src_pos, | |||||
| mel_pos=mel_pos, | |||||
| mel_max_length=max_mel_len, | |||||
| length_target=D) | |||||
| # print(mel_target.size()) | |||||
| # print(mel_output.size()) | |||||
| # Cal Loss | |||||
| mel_loss, mel_postnet_loss, duration_loss = fastspeech_loss(mel_output, | |||||
| mel_postnet_output, | |||||
| duration_predictor_output, | |||||
| mel_target, | |||||
| D) | |||||
| total_loss = mel_loss + mel_postnet_loss + duration_loss | |||||
| # Logger | |||||
| t_l = total_loss.item() | |||||
| m_l = mel_loss.item() | |||||
| m_p_l = mel_postnet_loss.item() | |||||
| d_l = duration_loss.item() | |||||
| with open(os.path.join("logger", "total_loss.txt"), "a") as f_total_loss: | |||||
| f_total_loss.write(str(t_l)+"\n") | |||||
| with open(os.path.join("logger", "mel_loss.txt"), "a") as f_mel_loss: | |||||
| f_mel_loss.write(str(m_l)+"\n") | |||||
| with open(os.path.join("logger", "mel_postnet_loss.txt"), "a") as f_mel_postnet_loss: | |||||
| f_mel_postnet_loss.write(str(m_p_l)+"\n") | |||||
| with open(os.path.join("logger", "duration_loss.txt"), "a") as f_d_loss: | |||||
| f_d_loss.write(str(d_l)+"\n") | |||||
| # Backward | |||||
| total_loss.backward() | |||||
| # Clipping gradients to avoid gradient explosion | |||||
| nn.utils.clip_grad_norm_( | |||||
| model.parameters(), hp.grad_clip_thresh) | |||||
| # Update weights | |||||
| if args.frozen_learning_rate: | |||||
| scheduled_optim.step_and_update_lr_frozen( | |||||
| args.learning_rate_frozen) | |||||
| else: | |||||
| scheduled_optim.step_and_update_lr() | |||||
| if current_step % hp.log_step == 0: | |||||
| Now = time.clock() | |||||
| str1 = "Epoch [{}/{}], Step [{}/{}]:".format( | |||||
| epoch+1, hp.epochs, current_step, total_step) | |||||
| str2 = "Mel Loss: {:.4f}, Mel PostNet Loss: {:.4f}, Duration Loss: {:.4f};".format( | |||||
| m_l, m_p_l, d_l) | |||||
| str3 = "Current Learning Rate is {:.6f}.".format( | |||||
| scheduled_optim.get_learning_rate()) | |||||
| str4 = "Time Used: {:.3f}s, Estimated Time Remaining: {:.3f}s.".format( | |||||
| (Now-Start), (total_step-current_step)*np.mean(Time)) | |||||
| print("\n" + str1) | |||||
| print(str2) | |||||
| print(str3) | |||||
| print(str4) | |||||
| with open(os.path.join("logger", "logger.txt"), "a") as f_logger: | |||||
| f_logger.write(str1 + "\n") | |||||
| f_logger.write(str2 + "\n") | |||||
| f_logger.write(str3 + "\n") | |||||
| f_logger.write(str4 + "\n") | |||||
| f_logger.write("\n") | |||||
| if current_step % hp.save_step == 0: | |||||
| torch.save({'model': model.state_dict(), 'optimizer': optimizer.state_dict( | |||||
| )}, os.path.join(hp.checkpoint_path, 'checkpoint_%d.pth.tar' % current_step)) | |||||
| print("save model at step %d ..." % current_step) | |||||
| end_time = time.clock() | |||||
| Time = np.append(Time, end_time - start_time) | |||||
| if len(Time) == hp.clear_Time: | |||||
| temp_value = np.mean(Time) | |||||
| Time = np.delete( | |||||
| Time, [i for i in range(len(Time))], axis=None) | |||||
| Time = np.append(Time, temp_value) | |||||
| if __name__ == "__main__": | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('--restore_step', type=int, default=0) | |||||
| parser.add_argument('--frozen_learning_rate', type=bool, default=False) | |||||
| parser.add_argument("--learning_rate_frozen", type=float, default=1e-3) | |||||
| args = parser.parse_args() | |||||
| main(args) | |||||
+ 100
- 0
FastSpeech/transformer/Beam.py
View File
| @ -0,0 +1,100 @@ | |||||
| import torch | |||||
| import numpy as np | |||||
| import transformer.Constants as Constants | |||||
| class Beam(): | |||||
| ''' Beam search ''' | |||||
| def __init__(self, size, device=False): | |||||
| self.size = size | |||||
| self._done = False | |||||
| # The score for each translation on the beam. | |||||
| self.scores = torch.zeros((size,), dtype=torch.float, device=device) | |||||
| self.all_scores = [] | |||||
| # The backpointers at each time-step. | |||||
| self.prev_ks = [] | |||||
| # The outputs at each time-step. | |||||
| self.next_ys = [torch.full( | |||||
| (size,), Constants.PAD, dtype=torch.long, device=device)] | |||||
| self.next_ys[0][0] = Constants.BOS | |||||
| def get_current_state(self): | |||||
| "Get the outputs for the current timestep." | |||||
| return self.get_tentative_hypothesis() | |||||
| def get_current_origin(self): | |||||
| "Get the backpointers for the current timestep." | |||||
| return self.prev_ks[-1] | |||||
| @property | |||||
| def done(self): | |||||
| return self._done | |||||
| def advance(self, word_prob): | |||||
| "Update beam status and check if finished or not." | |||||
| num_words = word_prob.size(1) | |||||
| # Sum the previous scores. | |||||
| if len(self.prev_ks) > 0: | |||||
| beam_lk = word_prob + self.scores.unsqueeze(1).expand_as(word_prob) | |||||
| else: | |||||
| beam_lk = word_prob[0] | |||||
| flat_beam_lk = beam_lk.view(-1) | |||||
| best_scores, best_scores_id = flat_beam_lk.topk( | |||||
| self.size, 0, True, True) # 1st sort | |||||
| best_scores, best_scores_id = flat_beam_lk.topk( | |||||
| self.size, 0, True, True) # 2nd sort | |||||
| self.all_scores.append(self.scores) | |||||
| self.scores = best_scores | |||||
| # bestScoresId is flattened as a (beam x word) array, | |||||
| # so we need to calculate which word and beam each score came from | |||||
| prev_k = best_scores_id / num_words | |||||
| self.prev_ks.append(prev_k) | |||||
| self.next_ys.append(best_scores_id - prev_k * num_words) | |||||
| # End condition is when top-of-beam is EOS. | |||||
| if self.next_ys[-1][0].item() == Constants.EOS: | |||||
| self._done = True | |||||
| self.all_scores.append(self.scores) | |||||
| return self._done | |||||
| def sort_scores(self): | |||||
| "Sort the scores." | |||||
| return torch.sort(self.scores, 0, True) | |||||
| def get_the_best_score_and_idx(self): | |||||
| "Get the score of the best in the beam." | |||||
| scores, ids = self.sort_scores() | |||||
| return scores[1], ids[1] | |||||
| def get_tentative_hypothesis(self): | |||||
| "Get the decoded sequence for the current timestep." | |||||
| if len(self.next_ys) == 1: | |||||
| dec_seq = self.next_ys[0].unsqueeze(1) | |||||
| else: | |||||
| _, keys = self.sort_scores() | |||||
| hyps = [self.get_hypothesis(k) for k in keys] | |||||
| hyps = [[Constants.BOS] + h for h in hyps] | |||||
| dec_seq = torch.LongTensor(hyps) | |||||
| return dec_seq | |||||
| def get_hypothesis(self, k): | |||||
| """ Walk back to construct the full hypothesis. """ | |||||
| hyp = [] | |||||
| for j in range(len(self.prev_ks) - 1, -1, -1): | |||||
| hyp.append(self.next_ys[j+1][k]) | |||||
| k = self.prev_ks[j][k] | |||||
| return list(map(lambda x: x.item(), hyp[::-1])) | |||||
+ 9
- 0
FastSpeech/transformer/Constants.py
View File
| @ -0,0 +1,9 @@ | |||||
| PAD = 0 | |||||
| UNK = 1 | |||||
| BOS = 2 | |||||
| EOS = 3 | |||||
| PAD_WORD = '<blank>' | |||||
| UNK_WORD = '<unk>' | |||||
| BOS_WORD = '<s>' | |||||
| EOS_WORD = '</s>' | |||||
+ 230
- 0
FastSpeech/transformer/Layers.py
View File
| @ -0,0 +1,230 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| from torch.nn import functional as F | |||||
| import numpy as np | |||||
| from collections import OrderedDict | |||||
| from transformer.SubLayers import MultiHeadAttention, PositionwiseFeedForward | |||||
| from text.symbols import symbols | |||||
| class Linear(nn.Module): | |||||
| """ | |||||
| Linear Module | |||||
| """ | |||||
| def __init__(self, in_dim, out_dim, bias=True, w_init='linear'): | |||||
| """ | |||||
| :param in_dim: dimension of input | |||||
| :param out_dim: dimension of output | |||||
| :param bias: boolean. if True, bias is included. | |||||
| :param w_init: str. weight inits with xavier initialization. | |||||
| """ | |||||
| super(Linear, self).__init__() | |||||
| self.linear_layer = nn.Linear(in_dim, out_dim, bias=bias) | |||||
| nn.init.xavier_uniform_( | |||||
| self.linear_layer.weight, | |||||
| gain=nn.init.calculate_gain(w_init)) | |||||
| def forward(self, x): | |||||
| return self.linear_layer(x) | |||||
| class PreNet(nn.Module): | |||||
| """ | |||||
| Pre Net before passing through the network | |||||
| """ | |||||
| def __init__(self, input_size, hidden_size, output_size, p=0.5): | |||||
| """ | |||||
| :param input_size: dimension of input | |||||
| :param hidden_size: dimension of hidden unit | |||||
| :param output_size: dimension of output | |||||
| """ | |||||
| super(PreNet, self).__init__() | |||||
| self.input_size = input_size | |||||
| self.output_size = output_size | |||||
| self.hidden_size = hidden_size | |||||
| self.layer = nn.Sequential(OrderedDict([ | |||||
| ('fc1', Linear(self.input_size, self.hidden_size)), | |||||
| ('relu1', nn.ReLU()), | |||||
| ('dropout1', nn.Dropout(p)), | |||||
| ('fc2', Linear(self.hidden_size, self.output_size)), | |||||
| ('relu2', nn.ReLU()), | |||||
| ('dropout2', nn.Dropout(p)), | |||||
| ])) | |||||
| def forward(self, input_): | |||||
| out = self.layer(input_) | |||||
| return out | |||||
| class Conv(nn.Module): | |||||
| """ | |||||
| Convolution Module | |||||
| """ | |||||
| def __init__(self, | |||||
| in_channels, | |||||
| out_channels, | |||||
| kernel_size=1, | |||||
| stride=1, | |||||
| padding=0, | |||||
| dilation=1, | |||||
| bias=True, | |||||
| w_init='linear'): | |||||
| """ | |||||
| :param in_channels: dimension of input | |||||
| :param out_channels: dimension of output | |||||
| :param kernel_size: size of kernel | |||||
| :param stride: size of stride | |||||
| :param padding: size of padding | |||||
| :param dilation: dilation rate | |||||
| :param bias: boolean. if True, bias is included. | |||||
| :param w_init: str. weight inits with xavier initialization. | |||||
| """ | |||||
| super(Conv, self).__init__() | |||||
| self.conv = nn.Conv1d(in_channels, | |||||
| out_channels, | |||||
| kernel_size=kernel_size, | |||||
| stride=stride, | |||||
| padding=padding, | |||||
| dilation=dilation, | |||||
| bias=bias) | |||||
| nn.init.xavier_uniform_( | |||||
| self.conv.weight, gain=nn.init.calculate_gain(w_init)) | |||||
| def forward(self, x): | |||||
| x = self.conv(x) | |||||
| return x | |||||
| class FFTBlock(torch.nn.Module): | |||||
| """FFT Block""" | |||||
| def __init__(self, | |||||
| d_model, | |||||
| d_inner, | |||||
| n_head, | |||||
| d_k, | |||||
| d_v, | |||||
| dropout=0.1): | |||||
| super(FFTBlock, self).__init__() | |||||
| self.slf_attn = MultiHeadAttention( | |||||
| n_head, d_model, d_k, d_v, dropout=dropout) | |||||
| self.pos_ffn = PositionwiseFeedForward( | |||||
| d_model, d_inner, dropout=dropout) | |||||
| def forward(self, enc_input, non_pad_mask=None, slf_attn_mask=None): | |||||
| enc_output, enc_slf_attn = self.slf_attn( | |||||
| enc_input, enc_input, enc_input, mask=slf_attn_mask) | |||||
| enc_output *= non_pad_mask | |||||
| enc_output = self.pos_ffn(enc_output) | |||||
| enc_output *= non_pad_mask | |||||
| return enc_output, enc_slf_attn | |||||
| class ConvNorm(torch.nn.Module): | |||||
| def __init__(self, | |||||
| in_channels, | |||||
| out_channels, | |||||
| kernel_size=1, | |||||
| stride=1, | |||||
| padding=None, | |||||
| dilation=1, | |||||
| bias=True, | |||||
| w_init_gain='linear'): | |||||
| super(ConvNorm, self).__init__() | |||||
| if padding is None: | |||||
| assert(kernel_size % 2 == 1) | |||||
| padding = int(dilation * (kernel_size - 1) / 2) | |||||
| self.conv = torch.nn.Conv1d(in_channels, | |||||
| out_channels, | |||||
| kernel_size=kernel_size, | |||||
| stride=stride, | |||||
| padding=padding, | |||||
| dilation=dilation, | |||||
| bias=bias) | |||||
| torch.nn.init.xavier_uniform_( | |||||
| self.conv.weight, gain=torch.nn.init.calculate_gain(w_init_gain)) | |||||
| def forward(self, signal): | |||||
| conv_signal = self.conv(signal) | |||||
| return conv_signal | |||||
| class PostNet(nn.Module): | |||||
| """ | |||||
| PostNet: Five 1-d convolution with 512 channels and kernel size 5 | |||||
| """ | |||||
| def __init__(self, | |||||
| n_mel_channels=80, | |||||
| postnet_embedding_dim=512, | |||||
| postnet_kernel_size=5, | |||||
| postnet_n_convolutions=5): | |||||
| super(PostNet, self).__init__() | |||||
| self.convolutions = nn.ModuleList() | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(n_mel_channels, | |||||
| postnet_embedding_dim, | |||||
| kernel_size=postnet_kernel_size, | |||||
| stride=1, | |||||
| padding=int((postnet_kernel_size - 1) / 2), | |||||
| dilation=1, | |||||
| w_init_gain='tanh'), | |||||
| nn.BatchNorm1d(postnet_embedding_dim)) | |||||
| ) | |||||
| for i in range(1, postnet_n_convolutions - 1): | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(postnet_embedding_dim, | |||||
| postnet_embedding_dim, | |||||
| kernel_size=postnet_kernel_size, | |||||
| stride=1, | |||||
| padding=int((postnet_kernel_size - 1) / 2), | |||||
| dilation=1, | |||||
| w_init_gain='tanh'), | |||||
| nn.BatchNorm1d(postnet_embedding_dim)) | |||||
| ) | |||||
| self.convolutions.append( | |||||
| nn.Sequential( | |||||
| ConvNorm(postnet_embedding_dim, | |||||
| n_mel_channels, | |||||
| kernel_size=postnet_kernel_size, | |||||
| stride=1, | |||||
| padding=int((postnet_kernel_size - 1) / 2), | |||||
| dilation=1, | |||||
| w_init_gain='linear'), | |||||
| nn.BatchNorm1d(n_mel_channels)) | |||||
| ) | |||||
| def forward(self, x): | |||||
| x = x.contiguous().transpose(1, 2) | |||||
| for i in range(len(self.convolutions) - 1): | |||||
| x = F.dropout(torch.tanh( | |||||
| self.convolutions[i](x)), 0.5, self.training) | |||||
| x = F.dropout(self.convolutions[-1](x), 0.5, self.training) | |||||
| x = x.contiguous().transpose(1, 2) | |||||
| return x | |||||
+ 145
- 0
FastSpeech/transformer/Models.py
View File
| @ -0,0 +1,145 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import numpy as np | |||||
| import transformer.Constants as Constants | |||||
| from transformer.Layers import FFTBlock, PreNet, PostNet, Linear | |||||
| from text.symbols import symbols | |||||
| import hparams as hp | |||||
| def get_non_pad_mask(seq): | |||||
| assert seq.dim() == 2 | |||||
| return seq.ne(Constants.PAD).type(torch.float).unsqueeze(-1) | |||||
| def get_sinusoid_encoding_table(n_position, d_hid, padding_idx=None): | |||||
| ''' Sinusoid position encoding table ''' | |||||
| def cal_angle(position, hid_idx): | |||||
| return position / np.power(10000, 2 * (hid_idx // 2) / d_hid) | |||||
| def get_posi_angle_vec(position): | |||||
| return [cal_angle(position, hid_j) for hid_j in range(d_hid)] | |||||
| sinusoid_table = np.array([get_posi_angle_vec(pos_i) | |||||
| for pos_i in range(n_position)]) | |||||
| sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i | |||||
| sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 | |||||
| if padding_idx is not None: | |||||
| # zero vector for padding dimension | |||||
| sinusoid_table[padding_idx] = 0. | |||||
| return torch.FloatTensor(sinusoid_table) | |||||
| def get_attn_key_pad_mask(seq_k, seq_q): | |||||
| ''' For masking out the padding part of key sequence. ''' | |||||
| # Expand to fit the shape of key query attention matrix. | |||||
| len_q = seq_q.size(1) | |||||
| padding_mask = seq_k.eq(Constants.PAD) | |||||
| padding_mask = padding_mask.unsqueeze( | |||||
| 1).expand(-1, len_q, -1) # b x lq x lk | |||||
| return padding_mask | |||||
| class Encoder(nn.Module): | |||||
| ''' Encoder ''' | |||||
| def __init__(self, | |||||
| n_src_vocab=len(symbols)+1, | |||||
| len_max_seq=hp.max_sep_len, | |||||
| d_word_vec=hp.word_vec_dim, | |||||
| n_layers=hp.encoder_n_layer, | |||||
| n_head=hp.encoder_head, | |||||
| d_k=64, | |||||
| d_v=64, | |||||
| d_model=hp.word_vec_dim, | |||||
| d_inner=hp.encoder_conv1d_filter_size, | |||||
| dropout=hp.dropout): | |||||
| super(Encoder, self).__init__() | |||||
| n_position = len_max_seq + 1 | |||||
| self.src_word_emb = nn.Embedding( | |||||
| n_src_vocab, d_word_vec, padding_idx=Constants.PAD) | |||||
| self.position_enc = nn.Embedding.from_pretrained( | |||||
| get_sinusoid_encoding_table(n_position, d_word_vec, padding_idx=0), | |||||
| freeze=True) | |||||
| self.layer_stack = nn.ModuleList([FFTBlock( | |||||
| d_model, d_inner, n_head, d_k, d_v, dropout=dropout) for _ in range(n_layers)]) | |||||
| def forward(self, src_seq, src_pos, return_attns=False): | |||||
| enc_slf_attn_list = [] | |||||
| # -- Prepare masks | |||||
| slf_attn_mask = get_attn_key_pad_mask(seq_k=src_seq, seq_q=src_seq) | |||||
| non_pad_mask = get_non_pad_mask(src_seq) | |||||
| # -- Forward | |||||
| enc_output = self.src_word_emb(src_seq) + self.position_enc(src_pos) | |||||
| for enc_layer in self.layer_stack: | |||||
| enc_output, enc_slf_attn = enc_layer( | |||||
| enc_output, | |||||
| non_pad_mask=non_pad_mask, | |||||
| slf_attn_mask=slf_attn_mask) | |||||
| if return_attns: | |||||
| enc_slf_attn_list += [enc_slf_attn] | |||||
| return enc_output, non_pad_mask | |||||
| class Decoder(nn.Module): | |||||
| """ Decoder """ | |||||
| def __init__(self, | |||||
| len_max_seq=hp.max_sep_len, | |||||
| d_word_vec=hp.word_vec_dim, | |||||
| n_layers=hp.decoder_n_layer, | |||||
| n_head=hp.decoder_head, | |||||
| d_k=64, | |||||
| d_v=64, | |||||
| d_model=hp.word_vec_dim, | |||||
| d_inner=hp.decoder_conv1d_filter_size, | |||||
| dropout=hp.dropout): | |||||
| super(Decoder, self).__init__() | |||||
| n_position = len_max_seq + 1 | |||||
| self.position_enc = nn.Embedding.from_pretrained( | |||||
| get_sinusoid_encoding_table(n_position, d_word_vec, padding_idx=0), | |||||
| freeze=True) | |||||
| self.layer_stack = nn.ModuleList([FFTBlock( | |||||
| d_model, d_inner, n_head, d_k, d_v, dropout=dropout) for _ in range(n_layers)]) | |||||
| def forward(self, enc_seq, enc_pos, return_attns=False): | |||||
| dec_slf_attn_list = [] | |||||
| # -- Prepare masks | |||||
| slf_attn_mask = get_attn_key_pad_mask(seq_k=enc_pos, seq_q=enc_pos) | |||||
| non_pad_mask = get_non_pad_mask(enc_pos) | |||||
| # -- Forward | |||||
| dec_output = enc_seq + self.position_enc(enc_pos) | |||||
| for dec_layer in self.layer_stack: | |||||
| dec_output, dec_slf_attn = dec_layer( | |||||
| dec_output, | |||||
| non_pad_mask=non_pad_mask, | |||||
| slf_attn_mask=slf_attn_mask) | |||||
| if return_attns: | |||||
| dec_slf_attn_list += [dec_slf_attn] | |||||
| return dec_output | |||||
+ 27
- 0
FastSpeech/transformer/Modules.py
View File
| @ -0,0 +1,27 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import numpy as np | |||||
| class ScaledDotProductAttention(nn.Module): | |||||
| ''' Scaled Dot-Product Attention ''' | |||||
| def __init__(self, temperature, attn_dropout=0.1): | |||||
| super().__init__() | |||||
| self.temperature = temperature | |||||
| self.dropout = nn.Dropout(attn_dropout) | |||||
| self.softmax = nn.Softmax(dim=2) | |||||
| def forward(self, q, k, v, mask=None): | |||||
| attn = torch.bmm(q, k.transpose(1, 2)) | |||||
| attn = attn / self.temperature | |||||
| if mask is not None: | |||||
| attn = attn.masked_fill(mask, -np.inf) | |||||
| attn = self.softmax(attn) | |||||
| attn = self.dropout(attn) | |||||
| output = torch.bmm(attn, v) | |||||
| return output, attn | |||||
+ 97
- 0
FastSpeech/transformer/SubLayers.py
View File
| @ -0,0 +1,97 @@ | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| import numpy as np | |||||
| from transformer.Modules import ScaledDotProductAttention | |||||
| import hparams as hp | |||||
| class MultiHeadAttention(nn.Module): | |||||
| ''' Multi-Head Attention module ''' | |||||
| def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1): | |||||
| super().__init__() | |||||
| self.n_head = n_head | |||||
| self.d_k = d_k | |||||
| self.d_v = d_v | |||||
| self.w_qs = nn.Linear(d_model, n_head * d_k) | |||||
| self.w_ks = nn.Linear(d_model, n_head * d_k) | |||||
| self.w_vs = nn.Linear(d_model, n_head * d_v) | |||||
| nn.init.normal_(self.w_qs.weight, mean=0, | |||||
| std=np.sqrt(2.0 / (d_model + d_k))) | |||||
| nn.init.normal_(self.w_ks.weight, mean=0, | |||||
| std=np.sqrt(2.0 / (d_model + d_k))) | |||||
| nn.init.normal_(self.w_vs.weight, mean=0, | |||||
| std=np.sqrt(2.0 / (d_model + d_v))) | |||||
| self.attention = ScaledDotProductAttention( | |||||
| temperature=np.power(d_k, 0.5)) | |||||
| self.layer_norm = nn.LayerNorm(d_model) | |||||
| self.fc = nn.Linear(n_head * d_v, d_model) | |||||
| nn.init.xavier_normal_(self.fc.weight) | |||||
| self.dropout = nn.Dropout(dropout) | |||||
| def forward(self, q, k, v, mask=None): | |||||
| d_k, d_v, n_head = self.d_k, self.d_v, self.n_head | |||||
| sz_b, len_q, _ = q.size() | |||||
| sz_b, len_k, _ = k.size() | |||||
| sz_b, len_v, _ = v.size() | |||||
| residual = q | |||||
| q = self.w_qs(q).view(sz_b, len_q, n_head, d_k) | |||||
| k = self.w_ks(k).view(sz_b, len_k, n_head, d_k) | |||||
| v = self.w_vs(v).view(sz_b, len_v, n_head, d_v) | |||||
| q = q.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| len_q, d_k) # (n*b) x lq x dk | |||||
| k = k.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| len_k, d_k) # (n*b) x lk x dk | |||||
| v = v.permute(2, 0, 1, 3).contiguous().view(-1, | |||||
| len_v, d_v) # (n*b) x lv x dv | |||||
| mask = mask.repeat(n_head, 1, 1) # (n*b) x .. x .. | |||||
| output, attn = self.attention(q, k, v, mask=mask) | |||||
| output = output.view(n_head, sz_b, len_q, d_v) | |||||
| output = output.permute(1, 2, 0, 3).contiguous().view( | |||||
| sz_b, len_q, -1) # b x lq x (n*dv) | |||||
| output = self.dropout(self.fc(output)) | |||||
| output = self.layer_norm(output + residual) | |||||
| return output, attn | |||||
| class PositionwiseFeedForward(nn.Module): | |||||
| ''' A two-feed-forward-layer module ''' | |||||
| def __init__(self, d_in, d_hid, dropout=0.1): | |||||
| super().__init__() | |||||
| # Use Conv1D | |||||
| # position-wise | |||||
| self.w_1 = nn.Conv1d( | |||||
| d_in, d_hid, kernel_size=hp.fft_conv1d_kernel, padding=hp.fft_conv1d_padding) | |||||
| # position-wise | |||||
| self.w_2 = nn.Conv1d( | |||||
| d_hid, d_in, kernel_size=hp.fft_conv1d_kernel, padding=hp.fft_conv1d_padding) | |||||
| self.layer_norm = nn.LayerNorm(d_in) | |||||
| self.dropout = nn.Dropout(dropout) | |||||
| def forward(self, x): | |||||
| residual = x | |||||
| output = x.transpose(1, 2) | |||||
| output = self.w_2(F.relu(self.w_1(output))) | |||||
| output = output.transpose(1, 2) | |||||
| output = self.dropout(output) | |||||
| output = self.layer_norm(output + residual) | |||||
| return output | |||||
+ 6
- 0
FastSpeech/transformer/__init__.py
View File
| @ -0,0 +1,6 @@ | |||||
| import transformer.Constants | |||||
| import transformer.Modules | |||||
| import transformer.Layers | |||||
| import transformer.SubLayers | |||||
| import transformer.Models | |||||
| import transformer.Beam | |||||
+ 183
- 0
FastSpeech/utils.py
View File
| @ -0,0 +1,183 @@ | |||||
| import torch | |||||
| import torch.nn as nn | |||||
| import torch.nn.functional as F | |||||
| import numpy as np | |||||
| import matplotlib | |||||
| import matplotlib.pyplot as plt | |||||
| import os | |||||
| import tacotron2 as Tacotron2 | |||||
| import text | |||||
| import hparams | |||||
| def process_text(train_text_path): | |||||
| with open(train_text_path, "r", encoding="utf-8") as f: | |||||
| txt = [] | |||||
| for line in f.readlines(): | |||||
| txt.append(line) | |||||
| return txt | |||||
| def get_param_num(model): | |||||
| num_param = sum(param.numel() for param in model.parameters()) | |||||
| return num_param | |||||
| def plot_data(data, figsize=(12, 4)): | |||||
| _, axes = plt.subplots(1, len(data), figsize=figsize) | |||||
| for i in range(len(data)): | |||||
| axes[i].imshow(data[i], aspect='auto', | |||||
| origin='bottom', interpolation='none') | |||||
| if not os.path.exists("img"): | |||||
| os.mkdir("img") | |||||
| plt.savefig(os.path.join("img", "model_test.jpg")) | |||||
| def get_mask_from_lengths(lengths, max_len=None): | |||||
| if max_len == None: | |||||
| max_len = torch.max(lengths).item() | |||||
| ids = torch.arange(0, max_len, out=torch.cuda.LongTensor(max_len)) | |||||
| mask = (ids < lengths.unsqueeze(1)).byte() | |||||
| return mask | |||||
| def get_WaveGlow(): | |||||
| waveglow_path = os.path.join("waveglow", "pretrained_model") | |||||
| waveglow_path = os.path.join(waveglow_path, "waveglow_256channels.pt") | |||||
| wave_glow = torch.load(waveglow_path)['model'] | |||||
| wave_glow = wave_glow.remove_weightnorm(wave_glow) | |||||
| wave_glow.cuda().eval() | |||||
| for m in wave_glow.modules(): | |||||
| if 'Conv' in str(type(m)): | |||||
| setattr(m, 'padding_mode', 'zeros') | |||||
| return wave_glow | |||||
| def get_Tacotron2(): | |||||
| checkpoint_path = "tacotron2_statedict.pt" | |||||
| checkpoint_path = os.path.join(os.path.join( | |||||
| "Tacotron2", "pretrained_model"), checkpoint_path) | |||||
| model = Tacotron2.model.Tacotron2( | |||||
| Tacotron2.hparams.create_hparams()).cuda() | |||||
| model.load_state_dict(torch.load(checkpoint_path)['state_dict']) | |||||
| _ = model.cuda().eval() | |||||
| return model | |||||
| def get_D(alignment): | |||||
| D = np.array([0 for _ in range(np.shape(alignment)[1])]) | |||||
| for i in range(np.shape(alignment)[0]): | |||||
| max_index = alignment[i].tolist().index(alignment[i].max()) | |||||
| D[max_index] = D[max_index] + 1 | |||||
| return D | |||||
| def pad_1D(inputs, PAD=0): | |||||
| def pad_data(x, length, PAD): | |||||
| x_padded = np.pad(x, (0, length - x.shape[0]), | |||||
| mode='constant', | |||||
| constant_values=PAD) | |||||
| return x_padded | |||||
| max_len = max((len(x) for x in inputs)) | |||||
| padded = np.stack([pad_data(x, max_len, PAD) for x in inputs]) | |||||
| return padded | |||||
| def pad_2D(inputs, maxlen=None): | |||||
| def pad(x, max_len): | |||||
| PAD = 0 | |||||
| if np.shape(x)[0] > max_len: | |||||
| raise ValueError("not max_len") | |||||
| s = np.shape(x)[1] | |||||
| x_padded = np.pad(x, (0, max_len - np.shape(x)[0]), | |||||
| mode='constant', | |||||
| constant_values=PAD) | |||||
| return x_padded[:, :s] | |||||
| if maxlen: | |||||
| output = np.stack([pad(x, maxlen) for x in inputs]) | |||||
| else: | |||||
| max_len = max(np.shape(x)[0] for x in inputs) | |||||
| output = np.stack([pad(x, max_len) for x in inputs]) | |||||
| return output | |||||
| def pad(input_ele, mel_max_length=None): | |||||
| if mel_max_length: | |||||
| out_list = list() | |||||
| max_len = mel_max_length | |||||
| for i, batch in enumerate(input_ele): | |||||
| one_batch_padded = F.pad( | |||||
| batch, (0, 0, 0, max_len-batch.size(0)), "constant", 0.0) | |||||
| out_list.append(one_batch_padded) | |||||
| out_padded = torch.stack(out_list) | |||||
| return out_padded | |||||
| else: | |||||
| out_list = list() | |||||
| max_len = max([input_ele[i].size(0)for i in range(len(input_ele))]) | |||||
| for i, batch in enumerate(input_ele): | |||||
| one_batch_padded = F.pad( | |||||
| batch, (0, 0, 0, max_len-batch.size(0)), "constant", 0.0) | |||||
| out_list.append(one_batch_padded) | |||||
| out_padded = torch.stack(out_list) | |||||
| return out_padded | |||||
| def load_data(txt, mel, model): | |||||
| character = text.text_to_sequence(txt, hparams.text_cleaners) | |||||
| character = torch.from_numpy(np.stack([np.array(character)])).long().cuda() | |||||
| text_length = torch.Tensor([character.size(1)]).long().cuda() | |||||
| mel = torch.from_numpy(np.stack([mel.T])).float().cuda() | |||||
| max_len = mel.size(2) | |||||
| output_length = torch.Tensor([max_len]).long().cuda() | |||||
| inputs = character, text_length, mel, max_len, output_length | |||||
| with torch.no_grad(): | |||||
| [_, mel_tacotron2, _, alignment], cemb = model.forward(inputs) | |||||
| alignment = alignment[0].cpu().numpy() | |||||
| cemb = cemb[0].cpu().numpy() | |||||
| D = get_D(alignment) | |||||
| D = np.array(D) | |||||
| mel_tacotron2 = mel_tacotron2[0].cpu().numpy() | |||||
| return mel_tacotron2, cemb, D | |||||
| def load_data_from_tacotron2(txt, model): | |||||
| character = text.text_to_sequence(txt, hparams.text_cleaners) | |||||
| character = torch.from_numpy(np.stack([np.array(character)])).long().cuda() | |||||
| with torch.no_grad(): | |||||
| [_, mel, _, alignment], cemb = model.inference(character) | |||||
| alignment = alignment[0].cpu().numpy() | |||||
| cemb = cemb[0].cpu().numpy() | |||||
| D = get_D(alignment) | |||||
| D = np.array(D) | |||||
| mel = mel[0].cpu().numpy() | |||||
| return mel, cemb, D | |||||
+ 3
- 0
FastSpeech/waveglow/__init__.py
View File
| @ -0,0 +1,3 @@ | |||||
| import waveglow.inference | |||||
| import waveglow.mel2samp | |||||
| import waveglow.glow | |||||
+ 46
- 0
FastSpeech/waveglow/convert_model.py
View File
| @ -0,0 +1,46 @@ | |||||
| import sys | |||||
| import copy | |||||
| import torch | |||||
| def _check_model_old_version(model): | |||||
| if hasattr(model.WN[0], 'res_layers'): | |||||
| return True | |||||
| else: | |||||
| return False | |||||
| def update_model(old_model): | |||||
| if not _check_model_old_version(old_model): | |||||
| return old_model | |||||
| new_model = copy.deepcopy(old_model) | |||||
| for idx in range(0, len(new_model.WN)): | |||||
| wavenet = new_model.WN[idx] | |||||
| wavenet.res_skip_layers = torch.nn.ModuleList() | |||||
| n_channels = wavenet.n_channels | |||||
| n_layers = wavenet.n_layers | |||||
| for i in range(0, n_layers): | |||||
| if i < n_layers - 1: | |||||
| res_skip_channels = 2*n_channels | |||||
| else: | |||||
| res_skip_channels = n_channels | |||||
| res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1) | |||||
| skip_layer = torch.nn.utils.remove_weight_norm(wavenet.skip_layers[i]) | |||||
| if i < n_layers - 1: | |||||
| res_layer = torch.nn.utils.remove_weight_norm(wavenet.res_layers[i]) | |||||
| res_skip_layer.weight = torch.nn.Parameter(torch.cat([res_layer.weight, skip_layer.weight])) | |||||
| res_skip_layer.bias = torch.nn.Parameter(torch.cat([res_layer.bias, skip_layer.bias])) | |||||
| else: | |||||
| res_skip_layer.weight = torch.nn.Parameter(skip_layer.weight) | |||||
| res_skip_layer.bias = torch.nn.Parameter(skip_layer.bias) | |||||
| res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') | |||||
| wavenet.res_skip_layers.append(res_skip_layer) | |||||
| del wavenet.res_layers | |||||
| del wavenet.skip_layers | |||||
| return new_model | |||||
| if __name__ == '__main__': | |||||
| old_model_path = sys.argv[1] | |||||
| new_model_path = sys.argv[2] | |||||
| model = torch.load(old_model_path) | |||||
| model['model'] = update_model(model['model']) | |||||
| torch.save(model, new_model_path) | |||||
+ 310
- 0
FastSpeech/waveglow/glow.py
View File
| @ -0,0 +1,310 @@ | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import copy | |||||
| import torch | |||||
| from torch.autograd import Variable | |||||
| import torch.nn.functional as F | |||||
| @torch.jit.script | |||||
| def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): | |||||
| n_channels_int = n_channels[0] | |||||
| in_act = input_a+input_b | |||||
| t_act = torch.tanh(in_act[:, :n_channels_int, :]) | |||||
| s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) | |||||
| acts = t_act * s_act | |||||
| return acts | |||||
| class WaveGlowLoss(torch.nn.Module): | |||||
| def __init__(self, sigma=1.0): | |||||
| super(WaveGlowLoss, self).__init__() | |||||
| self.sigma = sigma | |||||
| def forward(self, model_output): | |||||
| z, log_s_list, log_det_W_list = model_output | |||||
| for i, log_s in enumerate(log_s_list): | |||||
| if i == 0: | |||||
| log_s_total = torch.sum(log_s) | |||||
| log_det_W_total = log_det_W_list[i] | |||||
| else: | |||||
| log_s_total = log_s_total + torch.sum(log_s) | |||||
| log_det_W_total += log_det_W_list[i] | |||||
| loss = torch.sum(z*z)/(2*self.sigma*self.sigma) - log_s_total - log_det_W_total | |||||
| return loss/(z.size(0)*z.size(1)*z.size(2)) | |||||
| class Invertible1x1Conv(torch.nn.Module): | |||||
| """ | |||||
| The layer outputs both the convolution, and the log determinant | |||||
| of its weight matrix. If reverse=True it does convolution with | |||||
| inverse | |||||
| """ | |||||
| def __init__(self, c): | |||||
| super(Invertible1x1Conv, self).__init__() | |||||
| self.conv = torch.nn.Conv1d(c, c, kernel_size=1, stride=1, padding=0, | |||||
| bias=False) | |||||
| # Sample a random orthonormal matrix to initialize weights | |||||
| W = torch.qr(torch.FloatTensor(c, c).normal_())[0] | |||||
| # Ensure determinant is 1.0 not -1.0 | |||||
| if torch.det(W) < 0: | |||||
| W[:,0] = -1*W[:,0] | |||||
| W = W.view(c, c, 1) | |||||
| self.conv.weight.data = W | |||||
| def forward(self, z, reverse=False): | |||||
| # shape | |||||
| batch_size, group_size, n_of_groups = z.size() | |||||
| W = self.conv.weight.squeeze() | |||||
| if reverse: | |||||
| if not hasattr(self, 'W_inverse'): | |||||
| # Reverse computation | |||||
| W_inverse = W.float().inverse() | |||||
| W_inverse = Variable(W_inverse[..., None]) | |||||
| if z.type() == 'torch.cuda.HalfTensor': | |||||
| W_inverse = W_inverse.half() | |||||
| self.W_inverse = W_inverse | |||||
| z = F.conv1d(z, self.W_inverse, bias=None, stride=1, padding=0) | |||||
| return z | |||||
| else: | |||||
| # Forward computation | |||||
| log_det_W = batch_size * n_of_groups * torch.logdet(W) | |||||
| z = self.conv(z) | |||||
| return z, log_det_W | |||||
| class WN(torch.nn.Module): | |||||
| """ | |||||
| This is the WaveNet like layer for the affine coupling. The primary difference | |||||
| from WaveNet is the convolutions need not be causal. There is also no dilation | |||||
| size reset. The dilation only doubles on each layer | |||||
| """ | |||||
| def __init__(self, n_in_channels, n_mel_channels, n_layers, n_channels, | |||||
| kernel_size): | |||||
| super(WN, self).__init__() | |||||
| assert(kernel_size % 2 == 1) | |||||
| assert(n_channels % 2 == 0) | |||||
| self.n_layers = n_layers | |||||
| self.n_channels = n_channels | |||||
| self.in_layers = torch.nn.ModuleList() | |||||
| self.res_skip_layers = torch.nn.ModuleList() | |||||
| self.cond_layers = torch.nn.ModuleList() | |||||
| start = torch.nn.Conv1d(n_in_channels, n_channels, 1) | |||||
| start = torch.nn.utils.weight_norm(start, name='weight') | |||||
| self.start = start | |||||
| # Initializing last layer to 0 makes the affine coupling layers | |||||
| # do nothing at first. This helps with training stability | |||||
| end = torch.nn.Conv1d(n_channels, 2*n_in_channels, 1) | |||||
| end.weight.data.zero_() | |||||
| end.bias.data.zero_() | |||||
| self.end = end | |||||
| for i in range(n_layers): | |||||
| dilation = 2 ** i | |||||
| padding = int((kernel_size*dilation - dilation)/2) | |||||
| in_layer = torch.nn.Conv1d(n_channels, 2*n_channels, kernel_size, | |||||
| dilation=dilation, padding=padding) | |||||
| in_layer = torch.nn.utils.weight_norm(in_layer, name='weight') | |||||
| self.in_layers.append(in_layer) | |||||
| cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels, 1) | |||||
| cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') | |||||
| self.cond_layers.append(cond_layer) | |||||
| # last one is not necessary | |||||
| if i < n_layers - 1: | |||||
| res_skip_channels = 2*n_channels | |||||
| else: | |||||
| res_skip_channels = n_channels | |||||
| res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1) | |||||
| res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') | |||||
| self.res_skip_layers.append(res_skip_layer) | |||||
| def forward(self, forward_input): | |||||
| audio, spect = forward_input | |||||
| audio = self.start(audio) | |||||
| for i in range(self.n_layers): | |||||
| acts = fused_add_tanh_sigmoid_multiply( | |||||
| self.in_layers[i](audio), | |||||
| self.cond_layers[i](spect), | |||||
| torch.IntTensor([self.n_channels])) | |||||
| res_skip_acts = self.res_skip_layers[i](acts) | |||||
| if i < self.n_layers - 1: | |||||
| audio = res_skip_acts[:,:self.n_channels,:] + audio | |||||
| skip_acts = res_skip_acts[:,self.n_channels:,:] | |||||
| else: | |||||
| skip_acts = res_skip_acts | |||||
| if i == 0: | |||||
| output = skip_acts | |||||
| else: | |||||
| output = skip_acts + output | |||||
| return self.end(output) | |||||
| class WaveGlow(torch.nn.Module): | |||||
| def __init__(self, n_mel_channels, n_flows, n_group, n_early_every, | |||||
| n_early_size, WN_config): | |||||
| super(WaveGlow, self).__init__() | |||||
| self.upsample = torch.nn.ConvTranspose1d(n_mel_channels, | |||||
| n_mel_channels, | |||||
| 1024, stride=256) | |||||
| assert(n_group % 2 == 0) | |||||
| self.n_flows = n_flows | |||||
| self.n_group = n_group | |||||
| self.n_early_every = n_early_every | |||||
| self.n_early_size = n_early_size | |||||
| self.WN = torch.nn.ModuleList() | |||||
| self.convinv = torch.nn.ModuleList() | |||||
| n_half = int(n_group/2) | |||||
| # Set up layers with the right sizes based on how many dimensions | |||||
| # have been output already | |||||
| n_remaining_channels = n_group | |||||
| for k in range(n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| n_half = n_half - int(self.n_early_size/2) | |||||
| n_remaining_channels = n_remaining_channels - self.n_early_size | |||||
| self.convinv.append(Invertible1x1Conv(n_remaining_channels)) | |||||
| self.WN.append(WN(n_half, n_mel_channels*n_group, **WN_config)) | |||||
| self.n_remaining_channels = n_remaining_channels # Useful during inference | |||||
| def forward(self, forward_input): | |||||
| """ | |||||
| forward_input[0] = mel_spectrogram: batch x n_mel_channels x frames | |||||
| forward_input[1] = audio: batch x time | |||||
| """ | |||||
| spect, audio = forward_input | |||||
| # Upsample spectrogram to size of audio | |||||
| spect = self.upsample(spect) | |||||
| assert(spect.size(2) >= audio.size(1)) | |||||
| if spect.size(2) > audio.size(1): | |||||
| spect = spect[:, :, :audio.size(1)] | |||||
| spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3) | |||||
| spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1) | |||||
| audio = audio.unfold(1, self.n_group, self.n_group).permute(0, 2, 1) | |||||
| output_audio = [] | |||||
| log_s_list = [] | |||||
| log_det_W_list = [] | |||||
| for k in range(self.n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| output_audio.append(audio[:,:self.n_early_size,:]) | |||||
| audio = audio[:,self.n_early_size:,:] | |||||
| audio, log_det_W = self.convinv[k](audio) | |||||
| log_det_W_list.append(log_det_W) | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:,:n_half,:] | |||||
| audio_1 = audio[:,n_half:,:] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| log_s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = torch.exp(log_s)*audio_1 + b | |||||
| log_s_list.append(log_s) | |||||
| audio = torch.cat([audio_0, audio_1],1) | |||||
| output_audio.append(audio) | |||||
| return torch.cat(output_audio,1), log_s_list, log_det_W_list | |||||
| def infer(self, spect, sigma=1.0): | |||||
| spect = self.upsample(spect) | |||||
| # trim conv artifacts. maybe pad spec to kernel multiple | |||||
| time_cutoff = self.upsample.kernel_size[0] - self.upsample.stride[0] | |||||
| spect = spect[:, :, :-time_cutoff] | |||||
| spect = spect.unfold(2, self.n_group, self.n_group).permute(0, 2, 1, 3) | |||||
| spect = spect.contiguous().view(spect.size(0), spect.size(1), -1).permute(0, 2, 1) | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| audio = torch.cuda.HalfTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| spect.size(2)).normal_() | |||||
| else: | |||||
| audio = torch.cuda.FloatTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| spect.size(2)).normal_() | |||||
| audio = torch.autograd.Variable(sigma*audio) | |||||
| for k in reversed(range(self.n_flows)): | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:,:n_half,:] | |||||
| audio_1 = audio[:,n_half:,:] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = (audio_1 - b)/torch.exp(s) | |||||
| audio = torch.cat([audio_0, audio_1],1) | |||||
| audio = self.convinv[k](audio, reverse=True) | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| z = torch.cuda.HalfTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_() | |||||
| else: | |||||
| z = torch.cuda.FloatTensor(spect.size(0), self.n_early_size, spect.size(2)).normal_() | |||||
| audio = torch.cat((sigma*z, audio),1) | |||||
| audio = audio.permute(0,2,1).contiguous().view(audio.size(0), -1).data | |||||
| return audio | |||||
| @staticmethod | |||||
| def remove_weightnorm(model): | |||||
| waveglow = model | |||||
| for WN in waveglow.WN: | |||||
| WN.start = torch.nn.utils.remove_weight_norm(WN.start) | |||||
| WN.in_layers = remove(WN.in_layers) | |||||
| WN.cond_layers = remove(WN.cond_layers) | |||||
| WN.res_skip_layers = remove(WN.res_skip_layers) | |||||
| return waveglow | |||||
| def remove(conv_list): | |||||
| new_conv_list = torch.nn.ModuleList() | |||||
| for old_conv in conv_list: | |||||
| old_conv = torch.nn.utils.remove_weight_norm(old_conv) | |||||
| new_conv_list.append(old_conv) | |||||
| return new_conv_list | |||||
+ 57
- 0
FastSpeech/waveglow/inference.py
View File
| @ -0,0 +1,57 @@ | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" | |||||
| # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE | |||||
| # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE | |||||
| # ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import os | |||||
| from scipy.io.wavfile import write | |||||
| import torch | |||||
| from waveglow.mel2samp import files_to_list, MAX_WAV_VALUE | |||||
| # from denoiser import Denoiser | |||||
| def inference(mel, waveglow, audio_path, sigma=1.0, sampling_rate=22050): | |||||
| with torch.no_grad(): | |||||
| audio = waveglow.infer(mel, sigma=sigma) | |||||
| audio = audio * MAX_WAV_VALUE | |||||
| audio = audio.squeeze() | |||||
| audio = audio.cpu().numpy() | |||||
| audio = audio.astype('int16') | |||||
| write(audio_path, sampling_rate, audio) | |||||
| def test_speed(mel, waveglow, sigma=1.0, sampling_rate=22050): | |||||
| with torch.no_grad(): | |||||
| audio = waveglow.infer(mel, sigma=sigma) | |||||
| audio = audio * MAX_WAV_VALUE | |||||
| def get_wav(mel, waveglow, sigma=1.0, sampling_rate=22050): | |||||
| with torch.no_grad(): | |||||
| audio = waveglow.infer(mel, sigma=sigma) | |||||
| audio = audio * MAX_WAV_VALUE | |||||
| audio = audio.squeeze() | |||||
| audio = audio.cpu() | |||||
| return audio | |||||
+ 147
- 0
FastSpeech/waveglow/mel2samp.py
View File
| @ -0,0 +1,147 @@ | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # *****************************************************************************\ | |||||
| # from tacotron2.layers import TacotronSTFT | |||||
| import os | |||||
| import random | |||||
| import argparse | |||||
| import json | |||||
| import torch | |||||
| import torch.utils.data | |||||
| import sys | |||||
| from scipy.io.wavfile import read | |||||
| # We're using the audio processing from TacoTron2 to make sure it matches | |||||
| sys.path.insert(0, 'tacotron2') | |||||
| MAX_WAV_VALUE = 32768.0 | |||||
| def files_to_list(filename): | |||||
| """ | |||||
| Takes a text file of filenames and makes a list of filenames | |||||
| """ | |||||
| with open(filename, encoding='utf-8') as f: | |||||
| files = f.readlines() | |||||
| files = [f.rstrip() for f in files] | |||||
| return files | |||||
| # def load_wav_to_torch(full_path): | |||||
| # """ | |||||
| # Loads wavdata into torch array | |||||
| # """ | |||||
| # sampling_rate, data = read(full_path) | |||||
| # return torch.from_numpy(data).float(), sampling_rate | |||||
| # class Mel2Samp(torch.utils.data.Dataset): | |||||
| # """ | |||||
| # This is the main class that calculates the spectrogram and returns the | |||||
| # spectrogram, audio pair. | |||||
| # """ | |||||
| # def __init__(self, training_files, segment_length, filter_length, | |||||
| # hop_length, win_length, sampling_rate, mel_fmin, mel_fmax): | |||||
| # self.audio_files = files_to_list(training_files) | |||||
| # random.seed(1234) | |||||
| # random.shuffle(self.audio_files) | |||||
| # self.stft = TacotronSTFT(filter_length=filter_length, | |||||
| # hop_length=hop_length, | |||||
| # win_length=win_length, | |||||
| # sampling_rate=sampling_rate, | |||||
| # mel_fmin=mel_fmin, mel_fmax=mel_fmax) | |||||
| # self.segment_length = segment_length | |||||
| # self.sampling_rate = sampling_rate | |||||
| # def get_mel(self, audio): | |||||
| # audio_norm = audio / MAX_WAV_VALUE | |||||
| # audio_norm = audio_norm.unsqueeze(0) | |||||
| # audio_norm = torch.autograd.Variable(audio_norm, requires_grad=False) | |||||
| # melspec = self.stft.mel_spectrogram(audio_norm) | |||||
| # melspec = torch.squeeze(melspec, 0) | |||||
| # return melspec | |||||
| # def __getitem__(self, index): | |||||
| # # Read audio | |||||
| # filename = self.audio_files[index] | |||||
| # audio, sampling_rate = load_wav_to_torch(filename) | |||||
| # if sampling_rate != self.sampling_rate: | |||||
| # raise ValueError("{} SR doesn't match target {} SR".format( | |||||
| # sampling_rate, self.sampling_rate)) | |||||
| # # Take segment | |||||
| # if audio.size(0) >= self.segment_length: | |||||
| # max_audio_start = audio.size(0) - self.segment_length | |||||
| # audio_start = random.randint(0, max_audio_start) | |||||
| # audio = audio[audio_start:audio_start+self.segment_length] | |||||
| # else: | |||||
| # audio = torch.nn.functional.pad( | |||||
| # audio, (0, self.segment_length - audio.size(0)), 'constant').data | |||||
| # mel = self.get_mel(audio) | |||||
| # audio = audio / MAX_WAV_VALUE | |||||
| # return (mel, audio) | |||||
| # def __len__(self): | |||||
| # return len(self.audio_files) | |||||
| # # =================================================================== | |||||
| # # Takes directory of clean audio and makes directory of spectrograms | |||||
| # # Useful for making test sets | |||||
| # # =================================================================== | |||||
| # if __name__ == "__main__": | |||||
| # # Get defaults so it can work with no Sacred | |||||
| # parser = argparse.ArgumentParser() | |||||
| # parser.add_argument('-f', "--filelist_path", required=True) | |||||
| # parser.add_argument('-c', '--config', type=str, | |||||
| # help='JSON file for configuration') | |||||
| # parser.add_argument('-o', '--output_dir', type=str, | |||||
| # help='Output directory') | |||||
| # args = parser.parse_args() | |||||
| # with open(args.config) as f: | |||||
| # data = f.read() | |||||
| # data_config = json.loads(data)["data_config"] | |||||
| # mel2samp = Mel2Samp(**data_config) | |||||
| # filepaths = files_to_list(args.filelist_path) | |||||
| # # Make directory if it doesn't exist | |||||
| # if not os.path.isdir(args.output_dir): | |||||
| # os.makedirs(args.output_dir) | |||||
| # os.chmod(args.output_dir, 0o775) | |||||
| # for filepath in filepaths: | |||||
| # audio, sr = load_wav_to_torch(filepath) | |||||
| # melspectrogram = mel2samp.get_mel(audio) | |||||
| # filename = os.path.basename(filepath) | |||||
| # new_filepath = args.output_dir + '/' + filename + '.pt' | |||||
| # print(new_filepath) | |||||
| # torch.save(melspectrogram, new_filepath) | |||||
+ 129
- 0
SqueezeWave/README.md
View File
| @ -0,0 +1,129 @@ | |||||
| ## SqueezeWave: Extremely Lightweight Vocoders for On-device Speech Synthesis | |||||
| By Bohan Zhai *, Tianren Gao *, Flora Xue, Daniel Rothchild, Bichen Wu, Joseph Gonzalez, and Kurt Keutzer (UC Berkeley) | |||||
| Automatic speech synthesis is a challenging task that is becoming increasingly important as edge devices begin to interact with users through speech. Typical text-to-speech pipelines include a vocoder, which translates intermediate audio representations into an audio waveform. Most existing vocoders are difficult to parallelize since each generated sample is conditioned on previous samples. WaveGlow is a flow-based feed-forward alternative to these auto-regressive models (Prenger et al., 2019). However, while WaveGlow can be easily parallelized, the model is too expensive for real-time speech synthesis on the edge. This paper presents SqueezeWave, a family of lightweight vocoders based on WaveGlow that can generate audio of similar quality to WaveGlow with 61x - 214x fewer MACs. | |||||
| Link to the paper: [paper]. If you find this work useful, please consider citing | |||||
| ``` | |||||
| @inproceedings{squeezewave, | |||||
| Author = {Bohan Zhai, Tianren Gao, Flora Xue, Daniel Rothchild, Bichen Wu, Joseph Gonzalez, Kurt Keutzer}, | |||||
| Title = {SqueezeWave: Extremely Lightweight Vocoders for On-device Speech Synthesis}, | |||||
| Journal = {arXiv:2001.05685}, | |||||
| Year = {2020} | |||||
| } | |||||
| ``` | |||||
| ### Audio samples generated by SqueezeWave | |||||
| Audio samples of SqueezeWave are here: https://tianrengao.github.io/SqueezeWaveDemo/ | |||||
| ### Results | |||||
| We introduce 4 variants of SqueezeWave in our paper. See the table below. | |||||
| | Model | length | n_channels| MACs | Reduction | MOS | | |||||
| | --------------- | ------ | --------- | ----- | --------- | --------- | | |||||
| |WaveGlow | 2048 | 8 | 228.9 | 1x | 4.57±0.04 | | |||||
| |SqueezeWave-128L | 128 | 256 | 3.78 | 60x | 4.07±0.06 | | |||||
| |SqueezeWave-64L | 64 | 256 | 2.16 | 106x | 3.77±0.05 | | |||||
| |SqueezeWave-128S | 128 | 128 | 1.06 | 214x | 3.79±0.05 | | |||||
| |SqueezeWave-64S | 64 | 128 | 0.68 | 332x | 2.74±0.04 | | |||||
| ### Model Complexity | |||||
| A detailed MAC calculation can be found from [here](https://github.com/tianrengao/SqueezeWave/blob/master/SqueezeWave_computational_complexity.ipynb) | |||||
| ## Setup | |||||
| 0. (Optional) Create a virtual environment | |||||
| ``` | |||||
| virtualenv env | |||||
| source env/bin/activate | |||||
| ``` | |||||
| 1. Clone our repo and initialize submodule | |||||
| ```command | |||||
| git clone https://github.com/tianrengao/SqueezeWave.git | |||||
| cd SqueezeWave | |||||
| git submodule init | |||||
| git submodule update | |||||
| ``` | |||||
| 2. Install requirements | |||||
| ```pip3 install -r requirements.txt``` | |||||
| 3. Install [Apex] | |||||
| ```1 | |||||
| cd ../ | |||||
| git clone https://www.github.com/nvidia/apex | |||||
| cd apex | |||||
| python setup.py install | |||||
| ``` | |||||
| ## Generate audio with our pretrained model | |||||
| 1. Download our [pretrained models]. We provide 4 pretrained models as described in the paper. | |||||
| 2. Download [mel-spectrograms] | |||||
| 3. Generate audio. Please replace `SqueezeWave.pt` to the specific pretrained model's name. | |||||
| ```python3 inference.py -f <(ls mel_spectrograms/*.pt) -w SqueezeWave.pt -o . --is_fp16 -s 0.6``` | |||||
| ## Train your own model | |||||
| 1. Download [LJ Speech Data]. We assume all the waves are stored in the directory `^/data/` | |||||
| 2. Make a list of the file names to use for training/testing | |||||
| ```command | |||||
| ls data/*.wav | tail -n+10 > train_files.txt | |||||
| ls data/*.wav | head -n10 > test_files.txt | |||||
| ``` | |||||
| 3. We provide 4 model configurations with audio channel and channel numbers specified in the table below. The configuration files are under ```/configs``` directory. To choose the model you want to train, select the corresponding configuration file. | |||||
| 4. Train your SqueezeWave model | |||||
| ```command | |||||
| mkdir checkpoints | |||||
| python train.py -c configs/config_a256_c128.json | |||||
| ``` | |||||
| For multi-GPU training replace `train.py` with `distributed.py`. Only tested with single node and NCCL. | |||||
| For mixed precision training set `"fp16_run": true` on `config.json`. | |||||
| 5. Make test set mel-spectrograms | |||||
| ``` | |||||
| mkdir -p eval/mels | |||||
| python3 mel2samp.py -f test_files.txt -o eval/mels -c configs/config_a128_c256.json | |||||
| ``` | |||||
| 6. Run inference on the test data. | |||||
| ```command | |||||
| ls eval/mels > eval/mel_files.txt | |||||
| sed -i -e 's_.*_eval/mels/&_' eval/mel_files.txt | |||||
| mkdir -p eval/output | |||||
| python3 inference.py -f eval/mel_files.txt -w checkpoints/SqueezeWave_10000 -o eval/output --is_fp16 -s 0.6 | |||||
| ``` | |||||
| Replace `SqueezeWave_10000` with the checkpoint you want to test. | |||||
| ## Credits | |||||
| The implementation of this work is based on WaveGlow: https://github.com/NVIDIA/waveglow | |||||
| [//]: # (TODO) | |||||
| [//]: # (PROVIDE INSTRUCTIONS FOR DOWNLOADING LJS) | |||||
| [pytorch 1.0]: https://github.com/pytorch/pytorch#installation | |||||
| [website]: https://nv-adlr.github.io/WaveGlow | |||||
| [paper]: https://arxiv.org/abs/2001.05685 | |||||
| [WaveNet implementation]: https://github.com/r9y9/wavenet_vocoder | |||||
| [Glow]: https://blog.openai.com/glow/ | |||||
| [WaveNet]: https://deepmind.com/blog/wavenet-generative-model-raw-audio/ | |||||
| [PyTorch]: http://pytorch.org | |||||
| [pretrained models]: https://drive.google.com/file/d/1RyVMLY2l8JJGq_dCEAAd8rIRIn_k13UB/view?usp=sharing | |||||
| [mel-spectrograms]: https://drive.google.com/file/d/1g_VXK2lpP9J25dQFhQwx7doWl_p20fXA/view?usp=sharing | |||||
| [LJ Speech Data]: https://keithito.com/LJ-Speech-Dataset | |||||
| [Apex]: https://github.com/nvidia/apex | |||||
+ 445
- 0
SqueezeWave/SqueezeWave_computational_complexity.ipynb
View File
| @ -0,0 +1,445 @@ | |||||
| { | |||||
| "nbformat": 4, | |||||
| "nbformat_minor": 0, | |||||
| "metadata": { | |||||
| "colab": { | |||||
| "name": "SqueezeWave computational complexity.ipynb", | |||||
| "provenance": [] | |||||
| }, | |||||
| "kernelspec": { | |||||
| "name": "python2", | |||||
| "display_name": "Python 2" | |||||
| } | |||||
| }, | |||||
| "cells": [ | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "s8VYGy15fwqN", | |||||
| "colab_type": "code", | |||||
| "colab": {} | |||||
| }, | |||||
| "source": [ | |||||
| "import numpy as np" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": { | |||||
| "id": "MDp5WalGf5Ji", | |||||
| "colab_type": "text" | |||||
| }, | |||||
| "source": [ | |||||
| "**WaveGlow**" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "wrBBjKSYf89M", | |||||
| "colab_type": "code", | |||||
| "outputId": "4d77bc19-7a81-4f0b-bcad-65c42c4b2e9c", | |||||
| "colab": { | |||||
| "base_uri": "https://localhost:8080/", | |||||
| "height": 136 | |||||
| } | |||||
| }, | |||||
| "source": [ | |||||
| "L = 2048 # audio length\n", | |||||
| "n_audio_channel_init = 8 # initial audio channel \n", | |||||
| "C_mel = 80 * 8 # After upsampling and unfolding \n", | |||||
| "kernal_size = 3\n", | |||||
| "C_wn = 256 # input channel size of in_layer\n", | |||||
| "C_wn_middle = C_wn * 2 # output channel size of in_layer and cond_layer\n", | |||||
| "n_flows = 12\n", | |||||
| "n_layers = 8\n", | |||||
| "n_early_output = 2\n", | |||||
| "n_early_output_interval = 4\n", | |||||
| "duration = 0.725\n", | |||||
| "\n", | |||||
| "n_audio_channels = []\n", | |||||
| "n_audio = n_audio_channel_init\n", | |||||
| "for i in range(n_flows):\n", | |||||
| " if i % n_early_output_interval == 0 and i > 0:\n", | |||||
| " n_audio -= n_early_output\n", | |||||
| " n_audio_channels.append(n_audio) # audio channel after early output\n", | |||||
| "\n", | |||||
| "# in_layers\n", | |||||
| "WN_in_layers = L * kernal_size * C_wn * C_wn_middle * n_layers * n_flows\n", | |||||
| "print('MACs of in_layers', WN_in_layers / duration / 1e9)\n", | |||||
| "# cond layers\n", | |||||
| "WN_cond_layers = L * C_mel * C_wn_middle * n_layers * n_flows \n", | |||||
| "print('MACs of cond_layers', WN_cond_layers / duration / 1e9)\n", | |||||
| "# res skip layers\n", | |||||
| "WN_res_layers = (L * C_wn * C_wn_middle * (n_layers - 1) + L * C_wn * C_wn) * n_flows\n", | |||||
| "print('MACs of res_skip_layers', WN_res_layers / duration / 1e9)\n", | |||||
| "# invertible convs\n", | |||||
| "inv1x1 = np.sum([n**2 * L for n in n_audio_channels])\n", | |||||
| "print('MACs of invertible conv layers', inv1x1 / duration / 1e9)\n", | |||||
| "# start\n", | |||||
| "starts = np.sum([n / 2 * C_wn * L for n in n_audio_channels])\n", | |||||
| "print('MACs of start conv layers', starts / duration / 1e9)\n", | |||||
| "# end\n", | |||||
| "ends = np.sum([C_wn * n * L for n in n_audio_channels])\n", | |||||
| "print('MACs of end conv layers', ends / duration / 1e9)\n", | |||||
| "# total\n", | |||||
| "WG_total = WN_in_layers + WN_cond_layers + WN_res_layers + inv1x1 + starts + ends\n", | |||||
| "print('Total number of MACs is', WG_total / duration / 1e9)" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [ | |||||
| { | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "('MACs of in_layers', 106.63367079724138)\n", | |||||
| "('MACs of cond_layers', 88.86139233103448)\n", | |||||
| "('MACs of res_skip_layers', 33.32302212413793)\n", | |||||
| "('MACs of invertible conv layers', 0.00131072)\n", | |||||
| "('MACs of start conv layers', 0.02603361103448276)\n", | |||||
| "('MACs of end conv layers', 0.05206722206896552)\n", | |||||
| "('Total number of MACs is', 228.89749680551725)\n" | |||||
| ], | |||||
| "name": "stdout" | |||||
| } | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": { | |||||
| "id": "QRQheCWjgC9D", | |||||
| "colab_type": "text" | |||||
| }, | |||||
| "source": [ | |||||
| "SqueezeWave L=64, C=128" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "zSlwPlvUgJue", | |||||
| "colab_type": "code", | |||||
| "outputId": "18e282ea-a071-4117-ba08-6e6abdc36c68", | |||||
| "colab": { | |||||
| "base_uri": "https://localhost:8080/", | |||||
| "height": 153 | |||||
| } | |||||
| }, | |||||
| "source": [ | |||||
| "L = 64 # audio length\n", | |||||
| "n_audio_channel_init = 256 # initial audio channel \n", | |||||
| "L_mel = 64 # mel-spectrogram length\n", | |||||
| "C_mel =80 # mel-spectrogram channel \n", | |||||
| "kernal_size = 3\n", | |||||
| "C_wn = 128 # input channel size of in_layer\n", | |||||
| "C_wn_middle = C_wn * 2 # output channel size of in_layer and cond_layer\n", | |||||
| "n_flows = 12\n", | |||||
| "n_layers = 8\n", | |||||
| "n_early_output = 16\n", | |||||
| "n_early_output_interval = 2\n", | |||||
| "duration = 0.725\n", | |||||
| "\n", | |||||
| "n_audio_channels = []\n", | |||||
| "n_audio = n_audio_channel_init\n", | |||||
| "for i in range(n_flows):\n", | |||||
| " if i % n_early_output_interval == 0 and i > 0:\n", | |||||
| " n_audio -= n_early_output\n", | |||||
| " n_audio_channels.append(n_audio) # audio channel after early output\n", | |||||
| "\n", | |||||
| "# in_layers\n", | |||||
| "WN_in_layers = L * kernal_size * C_wn * n_layers * n_flows # depthwise\n", | |||||
| "WN_in_layers += L * C_wn * C_wn_middle * n_layers * n_flows # pointwise\n", | |||||
| "print('MACs of in_layers', WN_in_layers / duration / 1e9)\n", | |||||
| "# cond_layers\n", | |||||
| "WN_cond_layers = L_mel * C_mel * C_wn_middle * n_layers * n_flows\n", | |||||
| "print('MACs of cond_layers', WN_cond_layers / duration / 1e9)\n", | |||||
| "# res_skip_layers\n", | |||||
| "WN_res_layers = L * C_wn * C_wn * n_layers * n_flows\n", | |||||
| "print('MACs of res_skip_layers', WN_res_layers / duration / 1e9)\n", | |||||
| "# invertible convs\n", | |||||
| "inv1x1 = np.sum([n**2 * L for n in n_audio_channels])\n", | |||||
| "print('MACs of invertible conv layers', inv1x1 / duration / 1e9)\n", | |||||
| "# start\n", | |||||
| "starts = np.sum([n / 2 * C_wn * L for n in n_audio_channels])\n", | |||||
| "print('MACs of start conv layers', starts / duration / 1e9)\n", | |||||
| "#end\n", | |||||
| "ends = np.sum([C_wn * n * L for n in n_audio_channels])\n", | |||||
| "print('MACs of end conv layers', ends / duration / 1e9)\n", | |||||
| "# total\n", | |||||
| "total = WN_in_layers + WN_cond_layers + WN_res_layers + inv1x1 + starts + ends\n", | |||||
| "print('Total number of MACs is', total / duration / 1e9)\n", | |||||
| "print('Reduction compared with WaveGlow', WG_total / total)" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [ | |||||
| { | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "('MACs of in_layers', 0.2809460524137931)\n", | |||||
| "('MACs of cond_layers', 0.17355740689655172)\n", | |||||
| "('MACs of res_skip_layers', 0.1388459255172414)\n", | |||||
| "('MACs of invertible conv layers', 0.0502141351724138)\n", | |||||
| "('MACs of start conv layers', 0.014643906206896554)\n", | |||||
| "('MACs of end conv layers', 0.029287812413793107)\n", | |||||
| "('Total number of MACs is', 0.6874952386206896)\n", | |||||
| "('Reduction compared with WaveGlow', 332)\n" | |||||
| ], | |||||
| "name": "stdout" | |||||
| } | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": { | |||||
| "id": "M6K8zJ6cugYj", | |||||
| "colab_type": "text" | |||||
| }, | |||||
| "source": [ | |||||
| "**SqueezeWave L=64, C=256**" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "ju5Xa4oAhScO", | |||||
| "colab_type": "code", | |||||
| "outputId": "c91361be-ff73-4113-a584-6dda74c3690e", | |||||
| "colab": { | |||||
| "base_uri": "https://localhost:8080/", | |||||
| "height": 153 | |||||
| } | |||||
| }, | |||||
| "source": [ | |||||
| "L = 64 # audio length\n", | |||||
| "n_audio_channel_init = 256 # initial audio channel \n", | |||||
| "L_mel = 64 # mel-spectrogram length\n", | |||||
| "C_mel =80 # mel-spectrogram channel \n", | |||||
| "kernal_size = 3\n", | |||||
| "C_wn = 256 # input channel size of in_layer\n", | |||||
| "C_wn_middle = C_wn * 2 # output channel size of in_layer and cond_layer\n", | |||||
| "n_flows = 12\n", | |||||
| "n_layers = 8\n", | |||||
| "n_early_output = 16\n", | |||||
| "n_early_output_interval = 2\n", | |||||
| "duration = 0.725\n", | |||||
| "\n", | |||||
| "n_audio_channels = []\n", | |||||
| "n_audio = n_audio_channel_init\n", | |||||
| "for i in range(n_flows):\n", | |||||
| " if i % n_early_output_interval == 0 and i > 0:\n", | |||||
| " n_audio -= n_early_output\n", | |||||
| " n_audio_channels.append(n_audio) # audio channel after early output\n", | |||||
| "\n", | |||||
| "# in_layers\n", | |||||
| "WN_in_layers = L * kernal_size * C_wn * n_layers * n_flows # depthwise\n", | |||||
| "WN_in_layers += L * C_wn * C_wn_middle * n_layers * n_flows # pointwise\n", | |||||
| "print('MACs of in_layers', WN_in_layers / duration / 1e9)\n", | |||||
| "# cond_layers\n", | |||||
| "WN_cond_layers = L_mel * C_mel * C_wn_middle * n_layers * n_flows\n", | |||||
| "print('MACs of cond_layers', WN_cond_layers / duration / 1e9)\n", | |||||
| "# res_skip_layers\n", | |||||
| "WN_res_layers = L * C_wn * C_wn * n_layers * n_flows\n", | |||||
| "print('MACs of res_skip_layers', WN_res_layers / duration / 1e9)\n", | |||||
| "# invertible convs\n", | |||||
| "inv1x1 = np.sum([n**2 * L for n in n_audio_channels])\n", | |||||
| "print('MACs of invertible conv layers', inv1x1 / duration / 1e9)\n", | |||||
| "# start\n", | |||||
| "starts = np.sum([n / 2 * C_wn * L for n in n_audio_channels])\n", | |||||
| "print('MACs of start conv layers', starts / duration / 1e9)\n", | |||||
| "#end\n", | |||||
| "ends = np.sum([C_wn * n * L for n in n_audio_channels])\n", | |||||
| "print('MACs of end conv layers', ends / duration / 1e9)\n", | |||||
| "# total\n", | |||||
| "total = WN_in_layers + WN_cond_layers + WN_res_layers + inv1x1 + starts + ends\n", | |||||
| "print('Total number of MACs is', total / duration / 1e9)\n", | |||||
| "print('Reduction compared with WaveGlow', WG_total / total)" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [ | |||||
| { | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "('MACs of in_layers', 1.1172758068965518)\n", | |||||
| "('MACs of cond_layers', 0.34711481379310344)\n", | |||||
| "('MACs of res_skip_layers', 0.5553837020689656)\n", | |||||
| "('MACs of invertible conv layers', 0.0502141351724138)\n", | |||||
| "('MACs of start conv layers', 0.029287812413793107)\n", | |||||
| "('MACs of end conv layers', 0.058575624827586215)\n", | |||||
| "('Total number of MACs is', 2.157851895172414)\n", | |||||
| "('Reduction compared with WaveGlow', 106)\n" | |||||
| ], | |||||
| "name": "stdout" | |||||
| } | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": { | |||||
| "id": "aIgnX6Yi4BFu", | |||||
| "colab_type": "text" | |||||
| }, | |||||
| "source": [ | |||||
| "**SqueezeWave L=128, C=128**" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "W-3Q5jW84F_t", | |||||
| "colab_type": "code", | |||||
| "outputId": "436038c3-f3f8-4989-eeec-eb59c154b183", | |||||
| "colab": { | |||||
| "base_uri": "https://localhost:8080/", | |||||
| "height": 153 | |||||
| } | |||||
| }, | |||||
| "source": [ | |||||
| "L = 128 # audio length\n", | |||||
| "n_audio_channel_init = 128 # initial audio channel \n", | |||||
| "L_mel = 64 # mel-spectrogram length\n", | |||||
| "C_mel =80 # mel-spectrogram channel \n", | |||||
| "kernal_size = 3\n", | |||||
| "C_wn = 128 # input channel size of in_layer\n", | |||||
| "C_wn_middle = C_wn * 2 # output channel size of in_layer and cond_layer\n", | |||||
| "n_flows = 12\n", | |||||
| "n_layers = 8\n", | |||||
| "n_early_output = 16\n", | |||||
| "n_early_output_interval = 2\n", | |||||
| "duration = 0.725\n", | |||||
| "\n", | |||||
| "n_audio_channels = []\n", | |||||
| "n_audio = n_audio_channel_init\n", | |||||
| "for i in range(n_flows):\n", | |||||
| " if i % n_early_output_interval == 0 and i > 0:\n", | |||||
| " n_audio -= n_early_output\n", | |||||
| " n_audio_channels.append(n_audio) # audio channel after early output\n", | |||||
| "\n", | |||||
| "# in_layers\n", | |||||
| "WN_in_layers = L * kernal_size * C_wn * n_layers * n_flows # depthwise\n", | |||||
| "WN_in_layers += L * C_wn * C_wn_middle * n_layers * n_flows # pointwise\n", | |||||
| "print('MACs of in_layers', WN_in_layers / duration / 1e9)\n", | |||||
| "# cond_layers\n", | |||||
| "WN_cond_layers = L_mel * C_mel * C_wn_middle * n_layers * n_flows\n", | |||||
| "print('MACs of cond_layers', WN_cond_layers / duration / 1e9)\n", | |||||
| "# res_skip_layers\n", | |||||
| "WN_res_layers = L * C_wn * C_wn * n_layers * n_flows\n", | |||||
| "print('MACs of res_skip_layers', WN_res_layers / duration / 1e9)\n", | |||||
| "# invertible convs\n", | |||||
| "inv1x1 = np.sum([n**2 * L for n in n_audio_channels])\n", | |||||
| "print('MACs of invertible conv layers', inv1x1 / duration / 1e9)\n", | |||||
| "# start\n", | |||||
| "starts = np.sum([n / 2 * C_wn * L for n in n_audio_channels])\n", | |||||
| "print('MACs of start conv layers', starts / duration / 1e9)\n", | |||||
| "#end\n", | |||||
| "ends = np.sum([C_wn * n * L for n in n_audio_channels])\n", | |||||
| "print('MACs of end conv layers', ends / duration / 1e9)\n", | |||||
| "# total\n", | |||||
| "total = WN_in_layers + WN_cond_layers + WN_res_layers + inv1x1 + starts + ends\n", | |||||
| "print('Total number of MACs is', total / duration / 1e9)\n", | |||||
| "print('Reduction compared with WaveGlow', WG_total / total)" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [ | |||||
| { | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "('MACs of in_layers', 0.5618921048275862)\n", | |||||
| "('MACs of cond_layers', 0.17355740689655172)\n", | |||||
| "('MACs of res_skip_layers', 0.2776918510344828)\n", | |||||
| "('MACs of invertible conv layers', 0.017988502068965517)\n", | |||||
| "('MACs of start conv layers', 0.011932071724137933)\n", | |||||
| "('MACs of end conv layers', 0.023864143448275865)\n", | |||||
| "('Total number of MACs is', 1.06692608)\n", | |||||
| "('Reduction compared with WaveGlow', 214)\n" | |||||
| ], | |||||
| "name": "stdout" | |||||
| } | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "markdown", | |||||
| "metadata": { | |||||
| "id": "1kWvIBWU4Vwm", | |||||
| "colab_type": "text" | |||||
| }, | |||||
| "source": [ | |||||
| "**SqueezeWave L=128, C=256**" | |||||
| ] | |||||
| }, | |||||
| { | |||||
| "cell_type": "code", | |||||
| "metadata": { | |||||
| "id": "6YM2bkC14WWc", | |||||
| "colab_type": "code", | |||||
| "outputId": "b1fd3d03-0135-400e-cfbc-28746c8d0cf0", | |||||
| "colab": { | |||||
| "base_uri": "https://localhost:8080/", | |||||
| "height": 153 | |||||
| } | |||||
| }, | |||||
| "source": [ | |||||
| "L = 128 # audio length\n", | |||||
| "n_audio_channel_init = 128 # initial audio channel \n", | |||||
| "L_mel = 64 # mel-spectrogram length\n", | |||||
| "C_mel =80 # mel-spectrogram channel \n", | |||||
| "kernal_size = 3\n", | |||||
| "C_wn = 256 # input channel size of in_layer\n", | |||||
| "C_wn_middle = C_wn * 2 # output channel size of in_layer and cond_layer\n", | |||||
| "n_flows = 12\n", | |||||
| "n_layers = 8\n", | |||||
| "n_early_output = 16\n", | |||||
| "n_early_output_interval = 2\n", | |||||
| "duration = 0.725\n", | |||||
| "\n", | |||||
| "n_audio_channels = []\n", | |||||
| "n_audio = n_audio_channel_init\n", | |||||
| "for i in range(n_flows):\n", | |||||
| " if i % n_early_output_interval == 0 and i > 0:\n", | |||||
| " n_audio -= n_early_output\n", | |||||
| " n_audio_channels.append(n_audio) # audio channel after early output\n", | |||||
| "\n", | |||||
| "# in_layers\n", | |||||
| "WN_in_layers = L * kernal_size * C_wn * n_layers * n_flows # depthwise\n", | |||||
| "WN_in_layers += L * C_wn * C_wn_middle * n_layers * n_flows # pointwise\n", | |||||
| "print('MACs of in_layers', WN_in_layers / duration / 1e9)\n", | |||||
| "# cond_layers\n", | |||||
| "WN_cond_layers = L_mel * C_mel * C_wn_middle * n_layers * n_flows\n", | |||||
| "print('MACs of cond_layers', WN_cond_layers / duration / 1e9)\n", | |||||
| "# res_skip_layers\n", | |||||
| "WN_res_layers = L * C_wn * C_wn * n_layers * n_flows\n", | |||||
| "print('MACs of res_skip_layers', WN_res_layers / duration / 1e9)\n", | |||||
| "# invertible convs\n", | |||||
| "inv1x1 = np.sum([n**2 * L for n in n_audio_channels])\n", | |||||
| "print('MACs of invertible conv layers', inv1x1 / duration / 1e9)\n", | |||||
| "# start\n", | |||||
| "starts = np.sum([n / 2 * C_wn * L for n in n_audio_channels])\n", | |||||
| "print('MACs of start conv layers', starts / duration / 1e9)\n", | |||||
| "#end\n", | |||||
| "ends = np.sum([C_wn * n * L for n in n_audio_channels])\n", | |||||
| "print('MACs of end conv layers', ends / duration / 1e9)\n", | |||||
| "# total\n", | |||||
| "total = WN_in_layers + WN_cond_layers + WN_res_layers + inv1x1 + starts + ends\n", | |||||
| "print('Total number of MACs is', total / duration / 1e9)\n", | |||||
| "print('Reduction compared with WaveGlow', WG_total / total)" | |||||
| ], | |||||
| "execution_count": 0, | |||||
| "outputs": [ | |||||
| { | |||||
| "output_type": "stream", | |||||
| "text": [ | |||||
| "('MACs of in_layers', 2.2345516137931036)\n", | |||||
| "('MACs of cond_layers', 0.34711481379310344)\n", | |||||
| "('MACs of res_skip_layers', 1.1107674041379312)\n", | |||||
| "('MACs of invertible conv layers', 0.017988502068965517)\n", | |||||
| "('MACs of start conv layers', 0.023864143448275865)\n", | |||||
| "('MACs of end conv layers', 0.04772828689655173)\n", | |||||
| "('Total number of MACs is', 3.7820147641379314)\n", | |||||
| "('Reduction compared with WaveGlow', 60)\n" | |||||
| ], | |||||
| "name": "stdout" | |||||
| } | |||||
| ] | |||||
| } | |||||
| ] | |||||
| } | |||||
+ 80
- 0
SqueezeWave/TacotronSTFT.py
View File
| @ -0,0 +1,80 @@ | |||||
| import torch | |||||
| from librosa.filters import mel as librosa_mel_fn | |||||
| from audio_processing import dynamic_range_compression | |||||
| from audio_processing import dynamic_range_decompression | |||||
| from stft import STFT | |||||
| class LinearNorm(torch.nn.Module): | |||||
| def __init__(self, in_dim, out_dim, bias=True, w_init_gain='linear'): | |||||
| super(LinearNorm, self).__init__() | |||||
| self.linear_layer = torch.nn.Linear(in_dim, out_dim, bias=bias) | |||||
| torch.nn.init.xavier_uniform( | |||||
| self.linear_layer.weight, | |||||
| gain=torch.nn.init.calculate_gain(w_init_gain)) | |||||
| def forward(self, x): | |||||
| return self.linear_layer(x) | |||||
| class ConvNorm(torch.nn.Module): | |||||
| def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, | |||||
| padding=None, dilation=1, bias=True, w_init_gain='linear'): | |||||
| super(ConvNorm, self).__init__() | |||||
| if padding is None: | |||||
| assert(kernel_size % 2 == 1) | |||||
| padding = int(dilation * (kernel_size - 1) / 2) | |||||
| self.conv = torch.nn.Conv1d(in_channels, out_channels, | |||||
| kernel_size=kernel_size, stride=stride, | |||||
| padding=padding, dilation=dilation, | |||||
| bias=bias) | |||||
| torch.nn.init.xavier_uniform( | |||||
| self.conv.weight, gain=torch.nn.init.calculate_gain(w_init_gain)) | |||||
| def forward(self, signal): | |||||
| conv_signal = self.conv(signal) | |||||
| return conv_signal | |||||
| class TacotronSTFT(torch.nn.Module): | |||||
| def __init__(self, filter_length=1024, hop_length=256, win_length=1024, | |||||
| n_mel_channels=80, sampling_rate=22050, mel_fmin=0.0, | |||||
| mel_fmax=None, n_group=256): | |||||
| super(TacotronSTFT, self).__init__() | |||||
| self.n_mel_channels = n_mel_channels | |||||
| self.sampling_rate = sampling_rate | |||||
| self.stft_fn = STFT(filter_length, hop_length, win_length, n_group=n_group) | |||||
| mel_basis = librosa_mel_fn( | |||||
| sampling_rate, filter_length, n_mel_channels, mel_fmin, mel_fmax) | |||||
| mel_basis = torch.from_numpy(mel_basis).float() | |||||
| self.register_buffer('mel_basis', mel_basis) | |||||
| def spectral_normalize(self, magnitudes): | |||||
| output = dynamic_range_compression(magnitudes) | |||||
| return output | |||||
| def spectral_de_normalize(self, magnitudes): | |||||
| output = dynamic_range_decompression(magnitudes) | |||||
| return output | |||||
| def mel_spectrogram(self, y): | |||||
| """Computes mel-spectrograms from a batch of waves | |||||
| PARAMS | |||||
| ------ | |||||
| y: Variable(torch.FloatTensor) with shape (B, T) in range [-1, 1] | |||||
| RETURNS | |||||
| ------- | |||||
| mel_output: torch.FloatTensor of shape (B, n_mel_channels, T) | |||||
| """ | |||||
| assert(torch.min(y.data) >= -1) | |||||
| assert(torch.max(y.data) <= 1) | |||||
| magnitudes, phases = self.stft_fn.transform(y) | |||||
| magnitudes = magnitudes.data | |||||
| mel_output = torch.matmul(self.mel_basis, magnitudes) | |||||
| mel_output = self.spectral_normalize(mel_output) | |||||
| return mel_output | |||||
+ 93
- 0
SqueezeWave/audio_processing.py
View File
| @ -0,0 +1,93 @@ | |||||
| import torch | |||||
| import numpy as np | |||||
| from scipy.signal import get_window | |||||
| import librosa.util as librosa_util | |||||
| def window_sumsquare(window, n_frames, hop_length=200, win_length=800, | |||||
| n_fft=800, dtype=np.float32, norm=None): | |||||
| """ | |||||
| # from librosa 0.6 | |||||
| Compute the sum-square envelope of a window function at a given hop length. | |||||
| This is used to estimate modulation effects induced by windowing | |||||
| observations in short-time fourier transforms. | |||||
| Parameters | |||||
| ---------- | |||||
| window : string, tuple, number, callable, or list-like | |||||
| Window specification, as in `get_window` | |||||
| n_frames : int > 0 | |||||
| The number of analysis frames | |||||
| hop_length : int > 0 | |||||
| The number of samples to advance between frames | |||||
| win_length : [optional] | |||||
| The length of the window function. By default, this matches `n_fft`. | |||||
| n_fft : int > 0 | |||||
| The length of each analysis frame. | |||||
| dtype : np.dtype | |||||
| The data type of the output | |||||
| Returns | |||||
| ------- | |||||
| wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))` | |||||
| The sum-squared envelope of the window function | |||||
| """ | |||||
| if win_length is None: | |||||
| win_length = n_fft | |||||
| n = n_fft + hop_length * (n_frames - 1) | |||||
| x = np.zeros(n, dtype=dtype) | |||||
| # Compute the squared window at the desired length | |||||
| win_sq = get_window(window, win_length, fftbins=True) | |||||
| win_sq = librosa_util.normalize(win_sq, norm=norm)**2 | |||||
| win_sq = librosa_util.pad_center(win_sq, n_fft) | |||||
| # Fill the envelope | |||||
| for i in range(n_frames): | |||||
| sample = i * hop_length | |||||
| x[sample:min(n, sample + n_fft)] += win_sq[:max(0, min(n_fft, n - sample))] | |||||
| return x | |||||
| def griffin_lim(magnitudes, stft_fn, n_iters=30): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| magnitudes: spectrogram magnitudes | |||||
| stft_fn: STFT class with transform (STFT) and inverse (ISTFT) methods | |||||
| """ | |||||
| angles = np.angle(np.exp(2j * np.pi * np.random.rand(*magnitudes.size()))) | |||||
| angles = angles.astype(np.float32) | |||||
| angles = torch.autograd.Variable(torch.from_numpy(angles)) | |||||
| signal = stft_fn.inverse(magnitudes, angles).squeeze(1) | |||||
| for i in range(n_iters): | |||||
| _, angles = stft_fn.transform(signal) | |||||
| signal = stft_fn.inverse(magnitudes, angles).squeeze(1) | |||||
| return signal | |||||
| def dynamic_range_compression(x, C=1, clip_val=1e-5): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| C: compression factor | |||||
| """ | |||||
| return torch.log(torch.clamp(x, min=clip_val) * C) | |||||
| def dynamic_range_decompression(x, C=1): | |||||
| """ | |||||
| PARAMS | |||||
| ------ | |||||
| C: compression factor used to compress | |||||
| """ | |||||
| return torch.exp(x) / C | |||||
+ 40
- 0
SqueezeWave/configs/config_a128_c128.json
View File
| @ -0,0 +1,40 @@ | |||||
| { | |||||
| "train_config": { | |||||
| "fp16_run": true, | |||||
| "output_directory": "checkpoints", | |||||
| "epochs": 100000, | |||||
| "learning_rate": 4e-4, | |||||
| "sigma": 1.0, | |||||
| "iters_per_checkpoint": 2000, | |||||
| "batch_size": 96, | |||||
| "seed": 1234, | |||||
| "checkpoint_path": "", | |||||
| "with_tensorboard": true | |||||
| }, | |||||
| "data_config": { | |||||
| "training_files": "train_files.txt", | |||||
| "segment_length": 16384, | |||||
| "sampling_rate": 22050, | |||||
| "filter_length": 1024, | |||||
| "hop_length": 256, | |||||
| "win_length": 1024, | |||||
| "mel_fmin": 0.0, | |||||
| "mel_fmax": 8000.0 | |||||
| }, | |||||
| "dist_config": { | |||||
| "dist_backend": "nccl", | |||||
| "dist_url": "tcp://localhost:54321" | |||||
| }, | |||||
| "squeezewave_config": { | |||||
| "n_mel_channels": 80, | |||||
| "n_flows": 12, | |||||
| "n_audio_channel": 128, | |||||
| "n_early_every": 2, | |||||
| "n_early_size": 16, | |||||
| "WN_config": { | |||||
| "n_layers": 8, | |||||
| "n_channels": 128, | |||||
| "kernel_size": 3 | |||||
| } | |||||
| } | |||||
| } | |||||
+ 40
- 0
SqueezeWave/configs/config_a128_c256.json
View File
| @ -0,0 +1,40 @@ | |||||
| { | |||||
| "train_config": { | |||||
| "fp16_run": true, | |||||
| "output_directory": "checkpoints", | |||||
| "epochs": 100000, | |||||
| "learning_rate": 4e-4, | |||||
| "sigma": 1.0, | |||||
| "iters_per_checkpoint": 2000, | |||||
| "batch_size": 96, | |||||
| "seed": 1234, | |||||
| "checkpoint_path": "checkpoints/Squeeze_244000", | |||||
| "with_tensorboard": true | |||||
| }, | |||||
| "data_config": { | |||||
| "training_files": "train_files.txt", | |||||
| "segment_length": 16384, | |||||
| "sampling_rate": 22050, | |||||
| "filter_length": 1024, | |||||
| "hop_length": 256, | |||||
| "win_length": 1024, | |||||
| "mel_fmin": 0.0, | |||||
| "mel_fmax": 8000.0 | |||||
| }, | |||||
| "dist_config": { | |||||
| "dist_backend": "nccl", | |||||
| "dist_url": "tcp://localhost:54321" | |||||
| }, | |||||
| "squeezewave_config": { | |||||
| "n_mel_channels": 80, | |||||
| "n_flows": 12, | |||||
| "n_audio_channel": 128, | |||||
| "n_early_every": 2, | |||||
| "n_early_size": 16, | |||||
| "WN_config": { | |||||
| "n_layers": 8, | |||||
| "n_channels": 256, | |||||
| "kernel_size": 3 | |||||
| } | |||||
| } | |||||
| } | |||||
+ 40
- 0
SqueezeWave/configs/config_a256_c128.json
View File
| @ -0,0 +1,40 @@ | |||||
| { | |||||
| "train_config": { | |||||
| "fp16_run": true, | |||||
| "output_directory": "checkpoints", | |||||
| "epochs": 100000, | |||||
| "learning_rate": 4e-4, | |||||
| "sigma": 1.0, | |||||
| "iters_per_checkpoint": 2000, | |||||
| "batch_size": 96, | |||||
| "seed": 1234, | |||||
| "checkpoint_path": "", | |||||
| "with_tensorboard": true | |||||
| }, | |||||
| "data_config": { | |||||
| "training_files": "train_files.txt", | |||||
| "segment_length": 16384, | |||||
| "sampling_rate": 22050, | |||||
| "filter_length": 1024, | |||||
| "hop_length": 256, | |||||
| "win_length": 1024, | |||||
| "mel_fmin": 0.0, | |||||
| "mel_fmax": 8000.0 | |||||
| }, | |||||
| "dist_config": { | |||||
| "dist_backend": "nccl", | |||||
| "dist_url": "tcp://localhost:54321" | |||||
| }, | |||||
| "squeezewave_config": { | |||||
| "n_mel_channels": 80, | |||||
| "n_flows": 12, | |||||
| "n_audio_channel": 256, | |||||
| "n_early_every": 2, | |||||
| "n_early_size": 16, | |||||
| "WN_config": { | |||||
| "n_layers": 8, | |||||
| "n_channels": 128, | |||||
| "kernel_size": 3 | |||||
| } | |||||
| } | |||||
| } | |||||
+ 40
- 0
SqueezeWave/configs/config_a256_c256.json
View File
| @ -0,0 +1,40 @@ | |||||
| { | |||||
| "train_config": { | |||||
| "fp16_run": true, | |||||
| "output_directory": "checkpoints", | |||||
| "epochs": 100000, | |||||
| "learning_rate": 4e-4, | |||||
| "sigma": 1.0, | |||||
| "iters_per_checkpoint": 2000, | |||||
| "batch_size": 96, | |||||
| "seed": 1234, | |||||
| "checkpoint_path": "", | |||||
| "with_tensorboard": true | |||||
| }, | |||||
| "data_config": { | |||||
| "training_files": "train_files.txt", | |||||
| "segment_length": 16384, | |||||
| "sampling_rate": 22050, | |||||
| "filter_length": 1024, | |||||
| "hop_length": 256, | |||||
| "win_length": 1024, | |||||
| "mel_fmin": 0.0, | |||||
| "mel_fmax": 8000.0 | |||||
| }, | |||||
| "dist_config": { | |||||
| "dist_backend": "nccl", | |||||
| "dist_url": "tcp://localhost:54321" | |||||
| }, | |||||
| "squeezewave_config": { | |||||
| "n_mel_channels": 80, | |||||
| "n_flows": 12, | |||||
| "n_audio_channel": 256, | |||||
| "n_early_every": 2, | |||||
| "n_early_size": 16, | |||||
| "WN_config": { | |||||
| "n_layers": 8, | |||||
| "n_channels": 256, | |||||
| "kernel_size": 3 | |||||
| } | |||||
| } | |||||
| } | |||||
+ 70
- 0
SqueezeWave/convert_model.py
View File
| @ -0,0 +1,70 @@ | |||||
| import sys | |||||
| import copy | |||||
| import torch | |||||
| def _check_model_old_version(model): | |||||
| if hasattr(model.WN[0], 'res_layers') or hasattr(model.WN[0], 'cond_layers'): | |||||
| return True | |||||
| else: | |||||
| return False | |||||
| def _update_model_res_skip(old_model, new_model): | |||||
| for idx in range(0, len(new_model.WN)): | |||||
| wavenet = new_model.WN[idx] | |||||
| n_channels = wavenet.n_channels | |||||
| n_layers = wavenet.n_layers | |||||
| wavenet.res_skip_layers = torch.nn.ModuleList() | |||||
| for i in range(0, n_layers): | |||||
| if i < n_layers - 1: | |||||
| res_skip_channels = 2*n_channels | |||||
| else: | |||||
| res_skip_channels = n_channels | |||||
| res_skip_layer = torch.nn.Conv1d(n_channels, res_skip_channels, 1) | |||||
| skip_layer = torch.nn.utils.remove_weight_norm(wavenet.skip_layers[i]) | |||||
| if i < n_layers - 1: | |||||
| res_layer = torch.nn.utils.remove_weight_norm(wavenet.res_layers[i]) | |||||
| res_skip_layer.weight = torch.nn.Parameter(torch.cat([res_layer.weight, skip_layer.weight])) | |||||
| res_skip_layer.bias = torch.nn.Parameter(torch.cat([res_layer.bias, skip_layer.bias])) | |||||
| else: | |||||
| res_skip_layer.weight = torch.nn.Parameter(skip_layer.weight) | |||||
| res_skip_layer.bias = torch.nn.Parameter(skip_layer.bias) | |||||
| res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') | |||||
| wavenet.res_skip_layers.append(res_skip_layer) | |||||
| del wavenet.res_layers | |||||
| del wavenet.skip_layers | |||||
| def _update_model_cond(old_model, new_model): | |||||
| for idx in range(0, len(new_model.WN)): | |||||
| wavenet = new_model.WN[idx] | |||||
| n_channels = wavenet.n_channels | |||||
| n_layers = wavenet.n_layers | |||||
| n_mel_channels = wavenet.cond_layers[0].weight.shape[1] | |||||
| cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels*n_layers, 1) | |||||
| cond_layer_weight = [] | |||||
| cond_layer_bias = [] | |||||
| for i in range(0, n_layers): | |||||
| _cond_layer = torch.nn.utils.remove_weight_norm(wavenet.cond_layers[i]) | |||||
| cond_layer_weight.append(_cond_layer.weight) | |||||
| cond_layer_bias.append(_cond_layer.bias) | |||||
| cond_layer.weight = torch.nn.Parameter(torch.cat(cond_layer_weight)) | |||||
| cond_layer.bias = torch.nn.Parameter(torch.cat(cond_layer_bias)) | |||||
| cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') | |||||
| wavenet.cond_layer = cond_layer | |||||
| del wavenet.cond_layers | |||||
| def update_model(old_model): | |||||
| if not _check_model_old_version(old_model): | |||||
| return old_model | |||||
| new_model = copy.deepcopy(old_model) | |||||
| if hasattr(old_model.WN[0], 'res_layers'): | |||||
| _update_model_res_skip(old_model, new_model) | |||||
| if hasattr(old_model.WN[0], 'cond_layers'): | |||||
| _update_model_cond(old_model, new_model) | |||||
| return new_model | |||||
| if __name__ == '__main__': | |||||
| old_model_path = sys.argv[1] | |||||
| new_model_path = sys.argv[2] | |||||
| model = torch.load(old_model_path) | |||||
| model['model'] = update_model(model['model']) | |||||
| torch.save(model, new_model_path) | |||||
+ 39
- 0
SqueezeWave/denoiser.py
View File
| @ -0,0 +1,39 @@ | |||||
| import sys | |||||
| import torch | |||||
| from stft import STFT | |||||
| class Denoiser(torch.nn.Module): | |||||
| """ Removes model bias from audio produced with squeezewave""" | |||||
| def __init__(self, squeezewave, filter_length=1024, n_overlap=4, | |||||
| win_length=1024, mode='zeros'): | |||||
| super(Denoiser, self).__init__() | |||||
| self.stft = STFT(filter_length=filter_length, | |||||
| hop_length=int(filter_length/n_overlap), | |||||
| win_length=win_length).cuda() | |||||
| if mode == 'zeros': | |||||
| mel_input = torch.zeros( | |||||
| (1, 80, 88), | |||||
| dtype=squeezewave.upsample.weight.dtype, | |||||
| device=squeezewave.upsample.weight.device) | |||||
| elif mode == 'normal': | |||||
| mel_input = torch.randn( | |||||
| (1, 80, 88), | |||||
| dtype=squeezewave.upsample.weight.dtype, | |||||
| device=squeezewave.upsample.weight.device) | |||||
| else: | |||||
| raise Exception("Mode {} if not supported".format(mode)) | |||||
| with torch.no_grad(): | |||||
| bias_audio = squeezewave.infer(mel_input, sigma=0.0).float() | |||||
| bias_spec, _ = self.stft.transform(bias_audio) | |||||
| self.register_buffer('bias_spec', bias_spec[:, :, 0][:, :, None]) | |||||
| def forward(self, audio, strength=0.1): | |||||
| audio_spec, audio_angles = self.stft.transform(audio.cuda().float()) | |||||
| audio_spec_denoised = audio_spec - self.bias_spec * strength | |||||
| audio_spec_denoised = torch.clamp(audio_spec_denoised, 0.0) | |||||
| audio_denoised = self.stft.inverse(audio_spec_denoised, audio_angles) | |||||
| return audio_denoised | |||||
+ 191
- 0
SqueezeWave/distributed.py
View File
| @ -0,0 +1,191 @@ | |||||
| # We retain the copyright notice by NVIDIA from the original code. However, we | |||||
| # we reserve our rights on the modifications based on the original code. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import os | |||||
| import sys | |||||
| import time | |||||
| import subprocess | |||||
| import argparse | |||||
| import torch | |||||
| import torch.distributed as dist | |||||
| from torch.autograd import Variable | |||||
| def reduce_tensor(tensor, num_gpus): | |||||
| rt = tensor.clone() | |||||
| dist.all_reduce(rt, op=dist.reduce_op.SUM) | |||||
| # rt /= (num_gpus*2) | |||||
| rt /=num_gpus | |||||
| return rt | |||||
| def init_distributed(rank, num_gpus, group_name, dist_backend, dist_url): | |||||
| assert torch.cuda.is_available(), "Distributed mode requires CUDA." | |||||
| print("Initializing Distributed") | |||||
| # Set cuda device so everything is done on the right GPU. | |||||
| torch.cuda.set_device(rank % torch.cuda.device_count()) | |||||
| # os.environ['MASTER_ADDR'] = '172.31.44.232' | |||||
| # os.environ['MASTER_PORT'] = '58217' | |||||
| # Initialize distributed communication | |||||
| dist.init_process_group(dist_backend, init_method=dist_url, | |||||
| world_size=num_gpus, rank=rank, | |||||
| group_name=group_name) | |||||
| def _flatten_dense_tensors(tensors): | |||||
| """Flatten dense tensors into a contiguous 1D buffer. Assume tensors are of | |||||
| same dense type. | |||||
| Since inputs are dense, the resulting tensor will be a concatenated 1D | |||||
| buffer. Element-wise operation on this buffer will be equivalent to | |||||
| operating individually. | |||||
| Arguments: | |||||
| tensors (Iterable[Tensor]): dense tensors to flatten. | |||||
| Returns: | |||||
| A contiguous 1D buffer containing input tensors. | |||||
| """ | |||||
| if len(tensors) == 1: | |||||
| return tensors[0].contiguous().view(-1) | |||||
| flat = torch.cat([t.contiguous().view(-1) for t in tensors], dim=0) | |||||
| return flat | |||||
| def _unflatten_dense_tensors(flat, tensors): | |||||
| """View a flat buffer using the sizes of tensors. Assume that tensors are of | |||||
| same dense type, and that flat is given by _flatten_dense_tensors. | |||||
| Arguments: | |||||
| flat (Tensor): flattened dense tensors to unflatten. | |||||
| tensors (Iterable[Tensor]): dense tensors whose sizes will be used to | |||||
| unflatten flat. | |||||
| Returns: | |||||
| Unflattened dense tensors with sizes same as tensors and values from | |||||
| flat. | |||||
| """ | |||||
| outputs = [] | |||||
| offset = 0 | |||||
| for tensor in tensors: | |||||
| numel = tensor.numel() | |||||
| outputs.append(flat.narrow(0, offset, numel).view_as(tensor)) | |||||
| offset += numel | |||||
| return tuple(outputs) | |||||
| def apply_gradient_allreduce(module): | |||||
| """ | |||||
| Modifies existing model to do gradient allreduce, but doesn't change class | |||||
| so you don't need "module" | |||||
| """ | |||||
| if not hasattr(dist, '_backend'): | |||||
| module.warn_on_half = True | |||||
| else: | |||||
| module.warn_on_half = True if dist._backend == dist.dist_backend.GLOO else False | |||||
| for p in module.state_dict().values(): | |||||
| if not torch.is_tensor(p): | |||||
| continue | |||||
| dist.broadcast(p, 0) | |||||
| def allreduce_params(): | |||||
| if(module.needs_reduction): | |||||
| module.needs_reduction = False | |||||
| buckets = {} | |||||
| for param in module.parameters(): | |||||
| if param.requires_grad and param.grad is not None: | |||||
| tp = type(param.data) | |||||
| if tp not in buckets: | |||||
| buckets[tp] = [] | |||||
| buckets[tp].append(param) | |||||
| if module.warn_on_half: | |||||
| if torch.cuda.HalfTensor in buckets: | |||||
| print("WARNING: gloo dist backend for half parameters may be extremely slow." + | |||||
| " It is recommended to use the NCCL backend in this case. This currently requires" + | |||||
| "PyTorch built from top of tree master.") | |||||
| module.warn_on_half = False | |||||
| for tp in buckets: | |||||
| bucket = buckets[tp] | |||||
| grads = [param.grad.data for param in bucket] | |||||
| coalesced = _flatten_dense_tensors(grads) | |||||
| dist.all_reduce(coalesced) | |||||
| coalesced /= dist.get_world_size() | |||||
| for buf, synced in zip(grads, _unflatten_dense_tensors(coalesced, grads)): | |||||
| buf.copy_(synced) | |||||
| for param in list(module.parameters()): | |||||
| def allreduce_hook(*unused): | |||||
| Variable._execution_engine.queue_callback(allreduce_params) | |||||
| if param.requires_grad: | |||||
| param.register_hook(allreduce_hook) | |||||
| dir(param) | |||||
| def set_needs_reduction(self, input, output): | |||||
| self.needs_reduction = True | |||||
| module.register_forward_hook(set_needs_reduction) | |||||
| return module | |||||
| def main(config, stdout_dir, args_str): | |||||
| args_list = ['-u'] | |||||
| args_list.append('train.py') | |||||
| args_list += args_str.split(' ') if len(args_str) > 0 else [] | |||||
| args_list.append('--config={}'.format(config)) | |||||
| num_gpus = torch.cuda.device_count() | |||||
| args_list.append('--num_gpus={}'.format(num_gpus)) | |||||
| args_list.append("--group_name=group_{}".format(time.strftime("%Y_%m_%d-%H%M%S"))) | |||||
| if not os.path.isdir(stdout_dir): | |||||
| os.makedirs(stdout_dir) | |||||
| os.chmod(stdout_dir, 0o775) | |||||
| workers = [] | |||||
| for i in range(num_gpus): | |||||
| args_list[-2] = '--rank={}'.format(i) | |||||
| stdout = None if i == 0 else open( | |||||
| os.path.join(stdout_dir, "GPU_{}.log".format(i)), "w") | |||||
| print(args_list) | |||||
| p = subprocess.Popen([str(sys.executable)]+args_list, stdout=stdout) | |||||
| workers.append(p) | |||||
| for p in workers: | |||||
| p.wait() | |||||
| if __name__ == '__main__': | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('-c', '--config', type=str, required=True, | |||||
| help='JSON file for configuration') | |||||
| parser.add_argument('-s', '--stdout_dir', type=str, default=".", | |||||
| help='directory to save stoud logs') | |||||
| parser.add_argument( | |||||
| '-a', '--args_str', type=str, default='', | |||||
| help='double quoted string with space separated key value pairs') | |||||
| args = parser.parse_args() | |||||
| main(args.config, args.stdout_dir, args.args_str) | |||||
+ 328
- 0
SqueezeWave/glow.py
View File
| @ -0,0 +1,328 @@ | |||||
| # We retain the copyright notice by NVIDIA from the original code. However, we | |||||
| # we reserve our rights on the modifications based on the original code. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import torch | |||||
| from torch.autograd import Variable | |||||
| import torch.nn.functional as F | |||||
| import numpy as np | |||||
| @torch.jit.script | |||||
| def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): | |||||
| n_channels_int = n_channels[0] | |||||
| in_act = input_a+input_b | |||||
| t_act = torch.tanh(in_act[:, :n_channels_int, :]) | |||||
| s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) | |||||
| acts = t_act * s_act | |||||
| return acts | |||||
| class Upsample1d(torch.nn.Module): | |||||
| def __init__(self, scale=2): | |||||
| super(Upsample1d, self).__init__() | |||||
| self.scale = scale | |||||
| def forward(self, x): | |||||
| y = F.interpolate( | |||||
| x, scale_factor=self.scale, mode='nearest') | |||||
| return y | |||||
| class SqueezeWaveLoss(torch.nn.Module): | |||||
| def __init__(self, sigma=1.0): | |||||
| super(SqueezeWaveLoss, self).__init__() | |||||
| self.sigma = sigma | |||||
| def forward(self, model_output): | |||||
| z, log_s_list, log_det_W_list = model_output | |||||
| for i, log_s in enumerate(log_s_list): | |||||
| if i == 0: | |||||
| log_s_total = torch.sum(log_s) | |||||
| log_det_W_total = log_det_W_list[i] | |||||
| else: | |||||
| log_s_total = log_s_total + torch.sum(log_s) | |||||
| log_det_W_total += log_det_W_list[i] | |||||
| loss = torch.sum(z*z)/(2*self.sigma*self.sigma) - log_s_total - log_det_W_total | |||||
| return loss/(z.size(0)*z.size(1)*z.size(2)) | |||||
| class Invertible1x1Conv(torch.nn.Module): | |||||
| """ | |||||
| The layer outputs both the convolution, and the log determinant | |||||
| of its weight matrix. If reverse=True it does convolution with | |||||
| inverse | |||||
| """ | |||||
| def __init__(self, c): | |||||
| super(Invertible1x1Conv, self).__init__() | |||||
| self.conv = torch.nn.Conv1d(c, c, kernel_size=1, stride=1, padding=0, | |||||
| bias=False) | |||||
| # Sample a random orthonormal matrix to initialize weights | |||||
| W = torch.qr(torch.FloatTensor(c, c).normal_())[0] | |||||
| # Ensure determinant is 1.0 not -1.0 | |||||
| if torch.det(W) < 0: | |||||
| W[:,0] = -1*W[:,0] | |||||
| W = W.view(c, c, 1) | |||||
| self.conv.weight.data = W | |||||
| def forward(self, z, reverse=False): | |||||
| # shape | |||||
| batch_size, group_size, n_of_groups = z.size() | |||||
| W = self.conv.weight.squeeze() | |||||
| if reverse: | |||||
| if not hasattr(self, 'W_inverse'): | |||||
| # Reverse computation | |||||
| W_inverse = W.float().inverse() | |||||
| W_inverse = Variable(W_inverse[..., None]) | |||||
| if z.type() == 'torch.cuda.HalfTensor': | |||||
| W_inverse = W_inverse.half() | |||||
| self.W_inverse = W_inverse | |||||
| z = F.conv1d(z, self.W_inverse, bias=None, stride=1, padding=0) | |||||
| return z | |||||
| else: | |||||
| # Forward computation | |||||
| log_det_W = batch_size * n_of_groups * torch.logdet(W) | |||||
| z = self.conv(z) | |||||
| return z, log_det_W | |||||
| class WN(torch.nn.Module): | |||||
| """ | |||||
| This is the WaveNet like layer for the affine coupling. The primary difference | |||||
| from WaveNet is the convolutions need not be causal. There is also no dilation | |||||
| size reset. The dilation only doubles on each layer | |||||
| """ | |||||
| def __init__(self, n_in_channels, n_mel_channels, n_layers, n_channels, | |||||
| kernel_size): | |||||
| super(WN, self).__init__() | |||||
| assert(kernel_size % 2 == 1) | |||||
| assert(n_channels % 2 == 0) | |||||
| self.n_layers = n_layers | |||||
| self.n_channels = n_channels | |||||
| self.in_layers = torch.nn.ModuleList() | |||||
| self.res_skip_layers = torch.nn.ModuleList() | |||||
| self.upsample = Upsample1d(2) | |||||
| start = torch.nn.Conv1d(n_in_channels, n_channels, 1) | |||||
| start = torch.nn.utils.weight_norm(start, name='weight') | |||||
| self.start = start | |||||
| end = torch.nn.Conv1d(n_channels, 2*n_in_channels, 1) | |||||
| end.weight.data.zero_() | |||||
| end.bias.data.zero_() | |||||
| self.end = end | |||||
| # cond_layer | |||||
| cond_layer = torch.nn.Conv1d(n_mel_channels, 2*n_channels*n_layers, 1) | |||||
| self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') | |||||
| for i in range(n_layers): | |||||
| dilation = 1 | |||||
| padding = int((kernel_size*dilation - dilation)/2) | |||||
| # depthwise separable convolution | |||||
| depthwise = torch.nn.Conv1d(n_channels, n_channels, 3, | |||||
| dilation=dilation, padding=padding, | |||||
| groups=n_channels).cuda() | |||||
| pointwise = torch.nn.Conv1d(n_channels, 2*n_channels, 1).cuda() | |||||
| bn = torch.nn.BatchNorm1d(n_channels) | |||||
| self.in_layers.append(torch.nn.Sequential(bn, depthwise, pointwise)) | |||||
| # res_skip_layer | |||||
| res_skip_layer = torch.nn.Conv1d(n_channels, n_channels, 1) | |||||
| res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') | |||||
| self.res_skip_layers.append(res_skip_layer) | |||||
| def forward(self, forward_input): | |||||
| audio, spect = forward_input | |||||
| audio = self.start(audio) | |||||
| n_channels_tensor = torch.IntTensor([self.n_channels]) | |||||
| # pass all the mel_spectrograms to cond_layer | |||||
| spect = self.cond_layer(spect) | |||||
| for i in range(self.n_layers): | |||||
| # split the corresponding mel_spectrogram | |||||
| spect_offset = i*2*self.n_channels | |||||
| spec = spect[:,spect_offset:spect_offset+2*self.n_channels,:] | |||||
| if audio.size(2) > spec.size(2): | |||||
| cond = self.upsample(spec) | |||||
| else: | |||||
| cond = spec | |||||
| acts = fused_add_tanh_sigmoid_multiply( | |||||
| self.in_layers[i](audio), | |||||
| cond, | |||||
| n_channels_tensor) | |||||
| # res_skip | |||||
| res_skip_acts = self.res_skip_layers[i](acts) | |||||
| audio = audio + res_skip_acts | |||||
| return self.end(audio) | |||||
| class SqueezeWave(torch.nn.Module): | |||||
| def __init__(self, n_mel_channels, n_flows, n_audio_channel, n_early_every, | |||||
| n_early_size, WN_config): | |||||
| super(SqueezeWave, self).__init__() | |||||
| assert(n_audio_channel % 2 == 0) | |||||
| self.n_flows = n_flows | |||||
| self.n_audio_channel = n_audio_channel | |||||
| self.n_early_every = n_early_every | |||||
| self.n_early_size = n_early_size | |||||
| self.WN = torch.nn.ModuleList() | |||||
| self.convinv = torch.nn.ModuleList() | |||||
| n_half = int(n_audio_channel / 2) | |||||
| # Set up layers with the right sizes based on how many dimensions | |||||
| # have been output already | |||||
| n_remaining_channels = n_audio_channel | |||||
| for k in range(n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| n_half = n_half - int(self.n_early_size/2) | |||||
| n_remaining_channels = n_remaining_channels - self.n_early_size | |||||
| self.convinv.append(Invertible1x1Conv(n_remaining_channels)) | |||||
| self.WN.append(WN(n_half, n_mel_channels, **WN_config)) | |||||
| self.n_remaining_channels = n_remaining_channels # Useful during inference | |||||
| def forward(self, forward_input): | |||||
| """ | |||||
| forward_input[0] = mel_spectrogram: batch x n_mel_channels x frames | |||||
| forward_input[1] = audio: batch x time | |||||
| """ | |||||
| spect, audio = forward_input | |||||
| audio = audio.unfold( | |||||
| 1, self.n_audio_channel, self.n_audio_channel).permute(0, 2, 1) | |||||
| output_audio = [] | |||||
| log_s_list = [] | |||||
| log_det_W_list = [] | |||||
| for k in range(self.n_flows): | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| output_audio.append(audio[:,:self.n_early_size,:]) | |||||
| audio = audio[:,self.n_early_size:,:] | |||||
| audio, log_det_W = self.convinv[k](audio) | |||||
| log_det_W_list.append(log_det_W) | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:,:n_half,:] | |||||
| audio_1 = audio[:,n_half:,:] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| log_s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = (torch.exp(log_s))*audio_1 + b | |||||
| log_s_list.append(log_s) | |||||
| audio = torch.cat([audio_0, audio_1], 1) | |||||
| output_audio.append(audio) | |||||
| return torch.cat(output_audio, 1), log_s_list, log_det_W_list | |||||
| def infer(self, spect, sigma=1.0): | |||||
| spect_size = spect.size() | |||||
| l = spect.size(2)*(256 // self.n_audio_channel) | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| audio = torch.cuda.HalfTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| l).normal_() | |||||
| else: | |||||
| audio = torch.cuda.FloatTensor(spect.size(0), | |||||
| self.n_remaining_channels, | |||||
| l).normal_() | |||||
| for k in reversed(range(self.n_flows)): | |||||
| n_half = int(audio.size(1)/2) | |||||
| audio_0 = audio[:,:n_half,:] | |||||
| audio_1 = audio[:,n_half:,:] | |||||
| output = self.WN[k]((audio_0, spect)) | |||||
| s = output[:, n_half:, :] | |||||
| b = output[:, :n_half, :] | |||||
| audio_1 = (audio_1 - b)/torch.exp(s) | |||||
| audio = torch.cat([audio_0, audio_1],1) | |||||
| audio = self.convinv[k](audio, reverse=True) | |||||
| if k % self.n_early_every == 0 and k > 0: | |||||
| if spect.type() == 'torch.cuda.HalfTensor': | |||||
| z = torch.cuda.HalfTensor(spect.size(0), self.n_early_size, l).normal_() | |||||
| else: | |||||
| z = torch.cuda.FloatTensor(spect.size(0), self.n_early_size, l).normal_() | |||||
| audio = torch.cat((sigma*z, audio),1) | |||||
| audio = audio.permute(0,2,1).contiguous().view(audio.size(0), -1).data | |||||
| return audio | |||||
| @staticmethod | |||||
| def remove_weightnorm(model): | |||||
| squeezewave = model | |||||
| for WN in squeezewave.WN: | |||||
| WN.start = torch.nn.utils.remove_weight_norm(WN.start) | |||||
| WN.in_layers = remove_batch_norm(WN.in_layers) | |||||
| WN.cond_layer = torch.nn.utils.remove_weight_norm(WN.cond_layer) | |||||
| WN.res_skip_layers = remove(WN.res_skip_layers) | |||||
| return squeezewave | |||||
| def fuse_conv_and_bn(conv, bn): | |||||
| fusedconv = torch.nn.Conv1d( | |||||
| conv.in_channels, | |||||
| conv.out_channels, | |||||
| kernel_size = conv.kernel_size, | |||||
| padding=conv.padding, | |||||
| bias=True, | |||||
| groups=conv.groups) | |||||
| w_conv = conv.weight.clone().view(conv.out_channels, -1) | |||||
| w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps+bn.running_var))) | |||||
| w_bn = w_bn.clone() | |||||
| fusedconv.weight.data = torch.mm(w_bn, w_conv).view(fusedconv.weight.size()) | |||||
| if conv.bias is not None: | |||||
| b_conv = conv.bias | |||||
| else: | |||||
| b_conv = torch.zeros( conv.weight.size(0) ) | |||||
| b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps)) | |||||
| b_bn = torch.unsqueeze(b_bn, 1) | |||||
| bn_3 = b_bn.expand(-1, 3) | |||||
| b = torch.matmul(w_conv, torch.transpose(bn_3, 0, 1))[range(b_bn.size()[0]), range(b_bn.size()[0])] | |||||
| fusedconv.bias.data = ( b_conv + b ) | |||||
| return fusedconv | |||||
| def remove_batch_norm(conv_list): | |||||
| new_conv_list = torch.nn.ModuleList() | |||||
| for old_conv in conv_list: | |||||
| depthwise = fuse_conv_and_bn(old_conv[1], old_conv[0]) | |||||
| pointwise = old_conv[2] | |||||
| new_conv_list.append(torch.nn.Sequential(depthwise, pointwise)) | |||||
| return new_conv_list | |||||
| def remove(conv_list): | |||||
| new_conv_list = torch.nn.ModuleList() | |||||
| for old_conv in conv_list: | |||||
| old_conv = torch.nn.utils.remove_weight_norm(old_conv) | |||||
| new_conv_list.append(old_conv) | |||||
| return new_conv_list | |||||
+ 87
- 0
SqueezeWave/inference.py
View File
| @ -0,0 +1,87 @@ | |||||
| # We retain the copyright notice by NVIDIA from the original code. However, we | |||||
| # we reserve our rights on the modifications based on the original code. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" | |||||
| # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE | |||||
| # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE | |||||
| # ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import os | |||||
| from scipy.io.wavfile import write | |||||
| import torch | |||||
| from mel2samp import files_to_list, MAX_WAV_VALUE | |||||
| from denoiser import Denoiser | |||||
| def main(mel_files, squeezewave_path, sigma, output_dir, sampling_rate, is_fp16, | |||||
| denoiser_strength): | |||||
| mel_files = files_to_list(mel_files) | |||||
| squeezewave = torch.load(squeezewave_path)['model'] | |||||
| squeezewave = squeezewave.remove_weightnorm(squeezewave) | |||||
| squeezewave.cuda().eval() | |||||
| if is_fp16: | |||||
| from apex import amp | |||||
| squeezewave, _ = amp.initialize(squeezewave, [], opt_level="O3") | |||||
| if denoiser_strength > 0: | |||||
| denoiser = Denoiser(squeezewave).cuda() | |||||
| for i, file_path in enumerate(mel_files): | |||||
| file_name = os.path.splitext(os.path.basename(file_path))[0] | |||||
| mel = torch.load(file_path) | |||||
| mel = torch.autograd.Variable(mel.cuda()) | |||||
| mel = torch.unsqueeze(mel, 0) | |||||
| mel = mel.half() if is_fp16 else mel | |||||
| with torch.no_grad(): | |||||
| audio = squeezewave.infer(mel, sigma=sigma).float() | |||||
| if denoiser_strength > 0: | |||||
| audio = denoiser(audio, denoiser_strength) | |||||
| audio = audio * MAX_WAV_VALUE | |||||
| audio = audio.squeeze() | |||||
| audio = audio.cpu().numpy() | |||||
| audio = audio.astype('int16') | |||||
| audio_path = os.path.join( | |||||
| output_dir, "{}_synthesis.wav".format(file_name)) | |||||
| write(audio_path, sampling_rate, audio) | |||||
| print(audio_path) | |||||
| if __name__ == "__main__": | |||||
| import argparse | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('-f', "--filelist_path", required=True) | |||||
| parser.add_argument('-w', '--squeezewave_path', | |||||
| help='Path to squeezewave decoder checkpoint with model') | |||||
| parser.add_argument('-o', "--output_dir", required=True) | |||||
| parser.add_argument("-s", "--sigma", default=1.0, type=float) | |||||
| parser.add_argument("--sampling_rate", default=22050, type=int) | |||||
| parser.add_argument("--is_fp16", action="store_true") | |||||
| parser.add_argument("-d", "--denoiser_strength", default=0.0, type=float, | |||||
| help='Removes model bias. Start with 0.1 and adjust') | |||||
| args = parser.parse_args() | |||||
| main(args.filelist_path, args.squeezewave_path, args.sigma, args.output_dir, | |||||
| args.sampling_rate, args.is_fp16, args.denoiser_strength) | |||||
+ 150
- 0
SqueezeWave/mel2samp.py
View File
| @ -0,0 +1,150 @@ | |||||
| # We retain the copyright notice by NVIDIA from the original code. However, we | |||||
| # we reserve our rights on the modifications based on the original code. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # *****************************************************************************\ | |||||
| import os | |||||
| import random | |||||
| import argparse | |||||
| import json | |||||
| import torch | |||||
| import torch.utils.data | |||||
| import sys | |||||
| from scipy.io.wavfile import read | |||||
| # We're using the audio processing from TacoTron2 to make sure it matches | |||||
| from TacotronSTFT import TacotronSTFT | |||||
| MAX_WAV_VALUE = 32768.0 | |||||
| def files_to_list(filename): | |||||
| """ | |||||
| Takes a text file of filenames and makes a list of filenames | |||||
| """ | |||||
| with open(filename, encoding='utf-8') as f: | |||||
| files = f.readlines() | |||||
| files = [f.rstrip() for f in files] | |||||
| return files | |||||
| def load_wav_to_torch(full_path): | |||||
| """ | |||||
| Loads wavdata into torch array | |||||
| """ | |||||
| sampling_rate, data = read(full_path) | |||||
| return torch.from_numpy(data).float(), sampling_rate | |||||
| class Mel2Samp(torch.utils.data.Dataset): | |||||
| """ | |||||
| This is the main class that calculates the spectrogram and returns the | |||||
| spectrogram, audio pair. | |||||
| """ | |||||
| def __init__(self, n_audio_channel, training_files, segment_length, | |||||
| filter_length, hop_length, win_length, sampling_rate, mel_fmin, | |||||
| mel_fmax): | |||||
| self.audio_files = files_to_list(training_files) | |||||
| random.seed(1234) | |||||
| random.shuffle(self.audio_files) | |||||
| self.stft = TacotronSTFT(filter_length=filter_length, | |||||
| hop_length=hop_length, | |||||
| win_length=win_length, | |||||
| sampling_rate=sampling_rate, | |||||
| mel_fmin=mel_fmin, mel_fmax=mel_fmax, | |||||
| n_group=n_audio_channel) | |||||
| self.segment_length = segment_length | |||||
| self.sampling_rate = sampling_rate | |||||
| def get_mel(self, audio): | |||||
| audio_norm = audio / MAX_WAV_VALUE | |||||
| audio_norm = audio_norm.unsqueeze(0) | |||||
| audio_norm = torch.autograd.Variable(audio_norm, requires_grad=False) | |||||
| melspec = self.stft.mel_spectrogram(audio_norm) | |||||
| melspec = torch.squeeze(melspec, 0) | |||||
| return melspec | |||||
| def __getitem__(self, index): | |||||
| # Read audio | |||||
| filename = self.audio_files[index] | |||||
| audio, sampling_rate = load_wav_to_torch(filename) | |||||
| if sampling_rate != self.sampling_rate: | |||||
| raise ValueError("{} SR doesn't match target {} SR".format( | |||||
| sampling_rate, self.sampling_rate)) | |||||
| # Take segment | |||||
| if audio.size(0) >= self.segment_length: | |||||
| max_audio_start = audio.size(0) - self.segment_length | |||||
| audio_start = random.randint(0, max_audio_start) | |||||
| audio = audio[audio_start:audio_start+self.segment_length] | |||||
| else: | |||||
| audio = torch.nn.functional.pad( | |||||
| audio, (0, self.segment_length - audio.size(0)), | |||||
| 'constant').data | |||||
| mel = self.get_mel(audio) | |||||
| audio = audio / MAX_WAV_VALUE | |||||
| return (mel, audio) | |||||
| def __len__(self): | |||||
| return len(self.audio_files) | |||||
| # =================================================================== | |||||
| # Takes directory of clean audio and makes directory of spectrograms | |||||
| # Useful for making test sets | |||||
| # =================================================================== | |||||
| if __name__ == "__main__": | |||||
| # Get defaults so it can work with no Sacred | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('-f', "--filelist_path", required=True) | |||||
| parser.add_argument('-c', '--config', type=str, | |||||
| help='JSON file for configuration') | |||||
| parser.add_argument('-o', '--output_dir', type=str, | |||||
| help='Output directory') | |||||
| args = parser.parse_args() | |||||
| with open(args.config) as f: | |||||
| data = f.read() | |||||
| config = json.loads(data) | |||||
| data_config = config["data_config"] | |||||
| squeezewave_config = config["squeezewave_config"] | |||||
| mel2samp = Mel2Samp(squeezewave_config['n_audio_channel'], **data_config) | |||||
| filepaths = files_to_list(args.filelist_path) | |||||
| # Make directory if it doesn't exist | |||||
| if not os.path.isdir(args.output_dir): | |||||
| os.makedirs(args.output_dir) | |||||
| os.chmod(args.output_dir, 0o775) | |||||
| for filepath in filepaths: | |||||
| audio, sr = load_wav_to_torch(filepath) | |||||
| melspectrogram = mel2samp.get_mel(audio) | |||||
| filename = os.path.basename(filepath) | |||||
| new_filepath = args.output_dir + '/' + filename + '.pt' | |||||
| print(new_filepath) | |||||
| torch.save(melspectrogram, new_filepath) | |||||
+ 8
- 0
SqueezeWave/requirements.txt
View File
| @ -0,0 +1,8 @@ | |||||
| torch==1.0 | |||||
| matplotlib==2.1.0 | |||||
| numpy==1.13.3 | |||||
| inflect==0.2.5 | |||||
| librosa==0.6.0 | |||||
| scipy==1.0.0 | |||||
| tensorboardX==1.1 | |||||
| Unidecode==1.0.22 | |||||
+ 147
- 0
SqueezeWave/stft.py
View File
| @ -0,0 +1,147 @@ | |||||
| """ | |||||
| We retain the copyright notice from the original author. However, we reserve | |||||
| our rights on the modifications based on the original code. | |||||
| BSD 3-Clause License | |||||
| Copyright (c) 2017, Prem Seetharaman | |||||
| All rights reserved. | |||||
| * Redistribution and use in source and binary forms, with or without | |||||
| modification, are permitted provided that the following conditions are met: | |||||
| * Redistributions of source code must retain the above copyright notice, | |||||
| this list of conditions and the following disclaimer. | |||||
| * Redistributions in binary form must reproduce the above copyright notice, this | |||||
| list of conditions and the following disclaimer in the | |||||
| documentation and/or other materials provided with the distribution. | |||||
| * Neither the name of the copyright holder nor the names of its | |||||
| contributors may be used to endorse or promote products derived from this | |||||
| software without specific prior written permission. | |||||
| THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR | |||||
| ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON | |||||
| ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| """ | |||||
| import torch | |||||
| import numpy as np | |||||
| import torch.nn.functional as F | |||||
| from torch.autograd import Variable | |||||
| from scipy.signal import get_window | |||||
| from librosa.util import pad_center, tiny | |||||
| from audio_processing import window_sumsquare | |||||
| class STFT(torch.nn.Module): | |||||
| """adapted from Prem Seetharaman's https://github.com/pseeth/pytorch-stft""" | |||||
| def __init__(self, filter_length=800, hop_length=200, win_length=800, | |||||
| window='hann', n_group=256): | |||||
| super(STFT, self).__init__() | |||||
| self.filter_length = filter_length | |||||
| self.hop_length = hop_length | |||||
| self.win_length = win_length | |||||
| self.window = window | |||||
| self.forward_transform = None | |||||
| self.n_group = n_group | |||||
| scale = self.filter_length / self.hop_length | |||||
| fourier_basis = np.fft.fft(np.eye(self.filter_length)) | |||||
| cutoff = int((self.filter_length / 2 + 1)) | |||||
| fourier_basis = np.vstack([np.real(fourier_basis[:cutoff, :]), | |||||
| np.imag(fourier_basis[:cutoff, :])]) | |||||
| forward_basis = torch.FloatTensor(fourier_basis[:, None, :]) | |||||
| inverse_basis = torch.FloatTensor( | |||||
| np.linalg.pinv(scale * fourier_basis).T[:, None, :]) | |||||
| if window is not None: | |||||
| assert(win_length >= filter_length) | |||||
| # get window and zero center pad it to filter_length | |||||
| fft_window = get_window(window, win_length, fftbins=True) | |||||
| fft_window = pad_center(fft_window, filter_length) | |||||
| fft_window = torch.from_numpy(fft_window).float() | |||||
| # window the bases | |||||
| forward_basis *= fft_window | |||||
| inverse_basis *= fft_window | |||||
| self.register_buffer('forward_basis', forward_basis.float()) | |||||
| self.register_buffer('inverse_basis', inverse_basis.float()) | |||||
| def transform(self, input_data): | |||||
| num_batches = input_data.size(0) | |||||
| num_samples = input_data.size(1) | |||||
| self.num_samples = num_samples | |||||
| # similar to librosa, reflect-pad the input | |||||
| input_data = input_data.view(num_batches, 1, num_samples) | |||||
| pad = ((64 - 1) * self.hop_length + self.filter_length - num_samples) // 2 | |||||
| if pad < 0: | |||||
| pad = self.filter_length // 2 | |||||
| input_data = F.pad( | |||||
| input_data.unsqueeze(1), | |||||
| (int(pad), int(pad), 0, 0), | |||||
| mode='reflect') | |||||
| input_data = input_data.squeeze(1) | |||||
| forward_transform = F.conv1d( | |||||
| input_data, | |||||
| Variable(self.forward_basis, requires_grad=False), | |||||
| stride=self.hop_length, | |||||
| padding=0) | |||||
| cutoff = int((self.filter_length / 2) + 1) | |||||
| real_part = forward_transform[:, :cutoff, :] | |||||
| imag_part = forward_transform[:, cutoff:, :] | |||||
| magnitude = torch.sqrt(real_part**2 + imag_part**2) | |||||
| phase = torch.autograd.Variable( | |||||
| torch.atan2(imag_part.data, real_part.data)) | |||||
| return magnitude, phase | |||||
| def inverse(self, magnitude, phase): | |||||
| recombine_magnitude_phase = torch.cat( | |||||
| [magnitude*torch.cos(phase), magnitude*torch.sin(phase)], dim=1) | |||||
| inverse_transform = F.conv_transpose1d( | |||||
| recombine_magnitude_phase, | |||||
| Variable(self.inverse_basis, requires_grad=False), | |||||
| stride=self.hop_length, | |||||
| padding=0) | |||||
| if self.window is not None: | |||||
| window_sum = window_sumsquare( | |||||
| self.window, magnitude.size(-1), hop_length=self.hop_length, | |||||
| win_length=self.win_length, n_fft=self.filter_length, | |||||
| dtype=np.float32) | |||||
| # remove modulation effects | |||||
| approx_nonzero_indices = torch.from_numpy( | |||||
| np.where(window_sum > tiny(window_sum))[0]) | |||||
| window_sum = torch.autograd.Variable( | |||||
| torch.from_numpy(window_sum), requires_grad=False) | |||||
| inverse_transform[:, :, approx_nonzero_indices] /= window_sum[approx_nonzero_indices] | |||||
| # scale by hop ratio | |||||
| inverse_transform *= float(self.filter_length) / self.hop_length | |||||
| inverse_transform = inverse_transform[:, :, int(self.filter_length/2):] | |||||
| inverse_transform = inverse_transform[:, :, :-int(self.filter_length/2):] | |||||
| return inverse_transform | |||||
| def forward(self, input_data): | |||||
| self.magnitude, self.phase = self.transform(input_data) | |||||
| reconstruction = self.inverse(self.magnitude, self.phase) | |||||
| return reconstruction | |||||
+ 203
- 0
SqueezeWave/train.py
View File
| @ -0,0 +1,203 @@ | |||||
| # We retain the copyright notice by NVIDIA from the original code. However, we | |||||
| # we reserve our rights on the modifications based on the original code. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. | |||||
| # | |||||
| # Redistribution and use in source and binary forms, with or without | |||||
| # modification, are permitted provided that the following conditions are met: | |||||
| # * Redistributions of source code must retain the above copyright | |||||
| # notice, this list of conditions and the following disclaimer. | |||||
| # * Redistributions in binary form must reproduce the above copyright | |||||
| # notice, this list of conditions and the following disclaimer in the | |||||
| # documentation and/or other materials provided with the distribution. | |||||
| # * Neither the name of the NVIDIA CORPORATION nor the | |||||
| # names of its contributors may be used to endorse or promote products | |||||
| # derived from this software without specific prior written permission. | |||||
| # | |||||
| # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND | |||||
| # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED | |||||
| # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE | |||||
| # DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY | |||||
| # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES | |||||
| # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; | |||||
| # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND | |||||
| # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT | |||||
| # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS | |||||
| # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. | |||||
| # | |||||
| # ***************************************************************************** | |||||
| import argparse | |||||
| import json | |||||
| import os | |||||
| import torch | |||||
| #=====START: ADDED FOR DISTRIBUTED====== | |||||
| from distributed import init_distributed, apply_gradient_allreduce, reduce_tensor | |||||
| from torch.utils.data.distributed import DistributedSampler | |||||
| #=====END: ADDED FOR DISTRIBUTED====== | |||||
| from torch.utils.data import DataLoader | |||||
| from glow import SqueezeWave, SqueezeWaveLoss | |||||
| from mel2samp import Mel2Samp | |||||
| def load_checkpoint( | |||||
| checkpoint_path, model, optimizer, n_flows, n_early_every, | |||||
| n_early_size, n_mel_channels, n_audio_channel, WN_config): | |||||
| assert os.path.isfile(checkpoint_path) | |||||
| checkpoint_dict = torch.load(checkpoint_path, map_location='cpu') | |||||
| iteration = checkpoint_dict['iteration'] | |||||
| #iteration = 1 | |||||
| optimizer.load_state_dict(checkpoint_dict['optimizer']) | |||||
| model_for_loading = checkpoint_dict['model'] | |||||
| state_dict = model_for_loading.state_dict() | |||||
| model.load_state_dict(state_dict, strict = False) | |||||
| print("Loaded checkpoint '{}' (iteration {})" .format(checkpoint_path, iteration)) | |||||
| return model, optimizer, iteration | |||||
| def save_checkpoint(model, optimizer, learning_rate, iteration, filepath): | |||||
| print("Saving model and optimizer state at iteration {} to {}".format( | |||||
| iteration, filepath)) | |||||
| model_for_saving = SqueezeWave(**squeezewave_config).cuda() | |||||
| model_for_saving.load_state_dict(model.state_dict()) | |||||
| torch.save({'model': model_for_saving, | |||||
| 'iteration': iteration, | |||||
| 'optimizer': optimizer.state_dict(), | |||||
| 'learning_rate': learning_rate}, filepath) | |||||
| def train(num_gpus, rank, group_name, output_directory, epochs, learning_rate, | |||||
| sigma, iters_per_checkpoint, batch_size, seed, fp16_run, | |||||
| checkpoint_path, with_tensorboard): | |||||
| torch.manual_seed(seed) | |||||
| torch.cuda.manual_seed(seed) | |||||
| #=====START: ADDED FOR DISTRIBUTED====== | |||||
| if num_gpus > 1: | |||||
| init_distributed(rank, num_gpus, group_name, **dist_config) | |||||
| #=====END: ADDED FOR DISTRIBUTED====== | |||||
| criterion = SqueezeWaveLoss(sigma) | |||||
| model = SqueezeWave(**squeezewave_config).cuda() | |||||
| print(model) | |||||
| pytorch_total_params = sum(p.numel() for p in model.parameters()) | |||||
| pytorch_total_params_train = sum(p.numel() for p in model.parameters() if p.requires_grad) | |||||
| print("param", pytorch_total_params) | |||||
| print("param trainable", pytorch_total_params_train) | |||||
| #=====START: ADDED FOR DISTRIBUTED====== | |||||
| if num_gpus > 1: | |||||
| model = apply_gradient_allreduce(model) | |||||
| #=====END: ADDED FOR DISTRIBUTED====== | |||||
| optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) | |||||
| if fp16_run: | |||||
| from apex import amp | |||||
| model, optimizer = amp.initialize(model, optimizer, opt_level='O1') | |||||
| # Load checkpoint if one exists | |||||
| iteration = 0 | |||||
| if checkpoint_path != "": | |||||
| model, optimizer, iteration = load_checkpoint(checkpoint_path, model, | |||||
| optimizer, **squeezewave_config) | |||||
| iteration += 1 # next iteration is iteration + 1 | |||||
| n_audio_channel = squeezewave_config["n_audio_channel"] | |||||
| trainset = Mel2Samp(n_audio_channel, **data_config) | |||||
| # =====START: ADDED FOR DISTRIBUTED====== | |||||
| train_sampler = DistributedSampler(trainset) if num_gpus > 1 else None | |||||
| # =====END: ADDED FOR DISTRIBUTED====== | |||||
| train_loader = DataLoader(trainset, num_workers=0, shuffle=False, | |||||
| sampler=train_sampler, | |||||
| batch_size=batch_size, | |||||
| pin_memory=False, | |||||
| drop_last=True) | |||||
| # Get shared output_directory ready | |||||
| if rank == 0: | |||||
| if not os.path.isdir(output_directory): | |||||
| os.makedirs(output_directory) | |||||
| os.chmod(output_directory, 0o775) | |||||
| print("output directory", output_directory) | |||||
| if with_tensorboard and rank == 0: | |||||
| from tensorboardX import SummaryWriter | |||||
| logger = SummaryWriter(os.path.join(output_directory, 'logs')) | |||||
| model.train() | |||||
| epoch_offset = max(0, int(iteration / len(train_loader))) | |||||
| # ================ MAIN TRAINNIG LOOP! =================== | |||||
| for epoch in range(epoch_offset, epochs): | |||||
| print("Epoch: {}".format(epoch)) | |||||
| for i, batch in enumerate(train_loader): | |||||
| model.zero_grad() | |||||
| mel, audio = batch | |||||
| mel = torch.autograd.Variable(mel.cuda()) | |||||
| audio = torch.autograd.Variable(audio.cuda()) | |||||
| outputs = model((mel, audio)) | |||||
| loss = criterion(outputs) | |||||
| if num_gpus > 1: | |||||
| reduced_loss = reduce_tensor(loss.data, num_gpus).item() | |||||
| else: | |||||
| reduced_loss = loss.item() | |||||
| if fp16_run: | |||||
| with amp.scale_loss(loss, optimizer) as scaled_loss: | |||||
| scaled_loss.backward() | |||||
| else: | |||||
| loss.backward() | |||||
| optimizer.step() | |||||
| print("{}:\t{:.9f}\t".format(iteration, reduced_loss)) | |||||
| if with_tensorboard and rank == 0: | |||||
| logger.add_scalar('training_loss', reduced_loss, i + len(train_loader) * epoch) | |||||
| if (iteration % iters_per_checkpoint == 0): | |||||
| if rank == 0: | |||||
| checkpoint_path = "{}/SqueezeWave_{}".format( | |||||
| output_directory, iteration) | |||||
| save_checkpoint(model, optimizer, learning_rate, iteration, | |||||
| checkpoint_path) | |||||
| iteration += 1 | |||||
| if __name__ == "__main__": | |||||
| parser = argparse.ArgumentParser() | |||||
| parser.add_argument('-c', '--config', type=str, | |||||
| help='JSON file for configuration') | |||||
| parser.add_argument('-r', '--rank', type=int, default=0, | |||||
| help='rank of process for distributed') | |||||
| parser.add_argument('-g', '--group_name', type=str, default='', | |||||
| help='name of group for distributed') | |||||
| args = parser.parse_args() | |||||
| # Parse configs. Globals nicer in this case | |||||
| with open(args.config) as f: | |||||
| data = f.read() | |||||
| config = json.loads(data) | |||||
| train_config = config["train_config"] | |||||
| global data_config | |||||
| data_config = config["data_config"] | |||||
| global dist_config | |||||
| dist_config = config["dist_config"] | |||||
| global squeezewave_config | |||||
| squeezewave_config = config["squeezewave_config"] | |||||
| num_gpus = torch.cuda.device_count() | |||||
| if num_gpus > 1: | |||||
| if args.group_name == '': | |||||
| print("WARNING: Multiple GPUs detected but no distributed group set") | |||||
| print("Only running 1 GPU. Use distributed.py for multiple GPUs") | |||||
| num_gpus = 1 | |||||
| if num_gpus == 1 and args.rank != 0: | |||||
| raise Exception("Doing single GPU training on rank > 0") | |||||
| torch.backends.cudnn.enabled = True | |||||
| torch.backends.cudnn.benchmark = False | |||||
| train(num_gpus, args.rank, args.group_name, **train_config) | |||||