Fork of https://github.com/alokprasad/fastspeech_squeezewave to also fix denoising in squeezewave
You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
 alokprasad
219e9e9c70
alokprasad
219e9e9c70
|
5 years ago | |
|---|---|---|
| .. | ||
| audio | 5 years ago | |
| data | 5 years ago | |
| img | 5 years ago | |
| results | 5 years ago | |
| tacotron2 | 5 years ago | |
| text | 5 years ago | |
| transformer | 5 years ago | |
| waveglow | 5 years ago | |
| .gitignore | 5 years ago | |
| LICENSE | 5 years ago | |
| README.md | 5 years ago | |
| alignments.zip | 5 years ago | |
| dataset.py | 5 years ago | |
| fastspeech.py | 5 years ago | |
| glow.py | 5 years ago | |
| hparams.py | 5 years ago | |
| loss.py | 5 years ago | |
| modules.py | 5 years ago | |
| optimizer.py | 5 years ago | |
| preprocess.py | 5 years ago | |
| synthesis.py | 5 years ago | |
| train.py | 5 years ago | |
| utils.py | 5 years ago | |
README.md
FastSpeech-Pytorch
The Implementation of FastSpeech Based on Pytorch.
Update
2019/10/23
- Fix bugs in alignment;
- Fix bugs in transformer;
- Fix bugs in LengthRegulator;
- Change the way to process audio;
- Use waveglow to synthesize.
Model
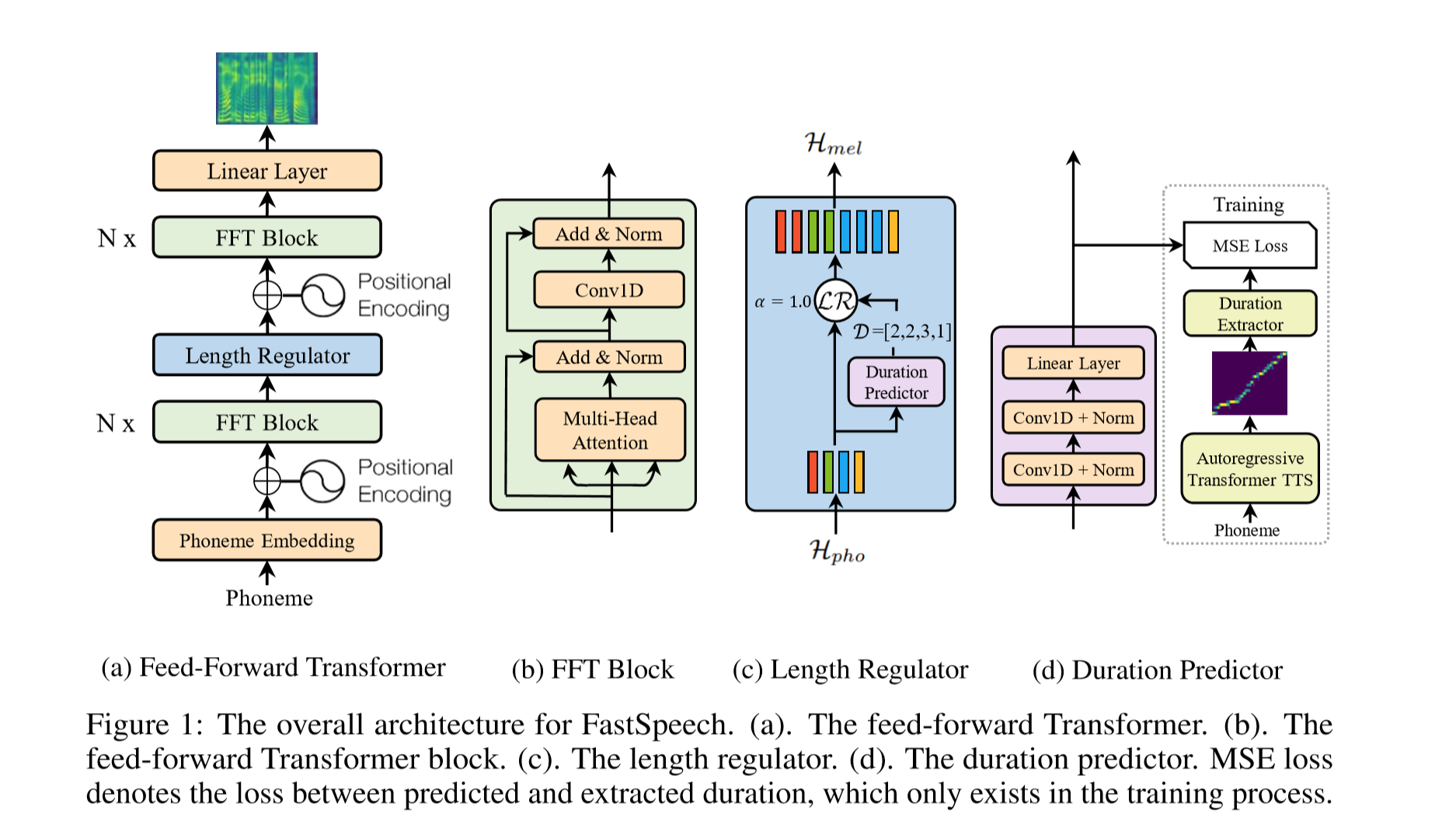
My Blog
Start
Dependencies
- python 3.6
- CUDA 10.0
- pytorch==1.1.0
- nump==1.16.2
- scipy==1.2.1
- librosa==0.6.3
- inflect==2.1.0
- matplotlib==2.2.2
Prepare Dataset
- Download and extract LJSpeech dataset.
- Put LJSpeech dataset in
data. - Unzip
alignments.zip* - Put Nvidia pretrained waveglow model in the
waveglow/pretrained_model; - Run
python preprocess.py.
* if you want to calculate alignment, don't unzip alignments.zip and put Nvidia pretrained Tacotron2 model in the Tacotron2/pretrained_model
Training
Run python train.py.
Test
Run python synthesis.py.
Pretrained Model
- Baidu: Step:112000 Enter Code: xpk7
- OneDrive: Step:112000
Notes
- In the paper of FastSpeech, authors use pre-trained Transformer-TTS to provide the target of alignment. I didn't have a well-trained Transformer-TTS model so I use Tacotron2 instead.
- The examples of audio are in
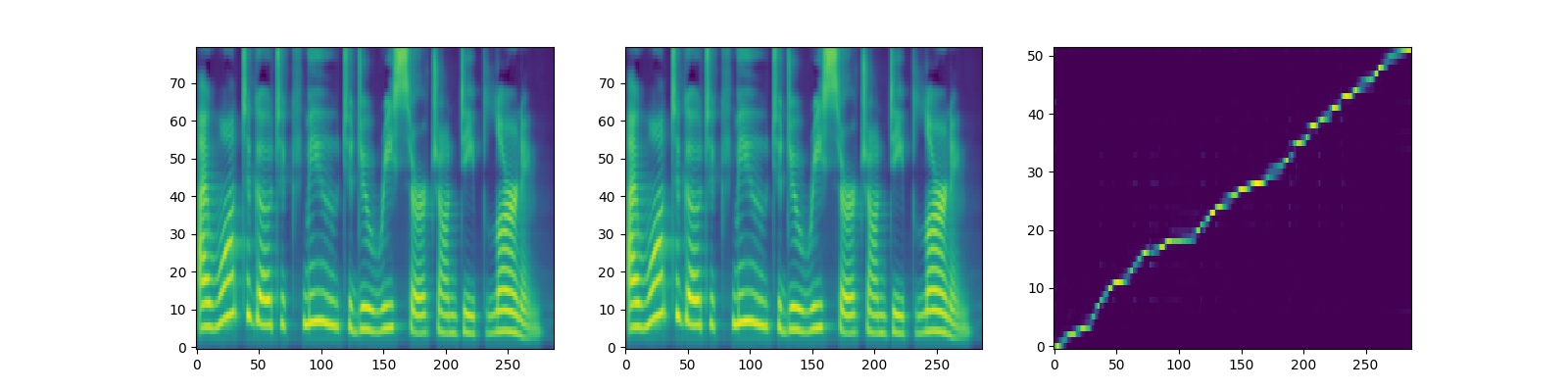
results. - The outputs and alignment of Tacotron2 are shown as follows (The sentence for synthesizing is "I want to go to CMU to do research on deep learning."):
- The outputs of FastSpeech and Tacotron2 (Right one is tacotron2) are shown as follows (The sentence for synthesizing is "Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition."):